How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


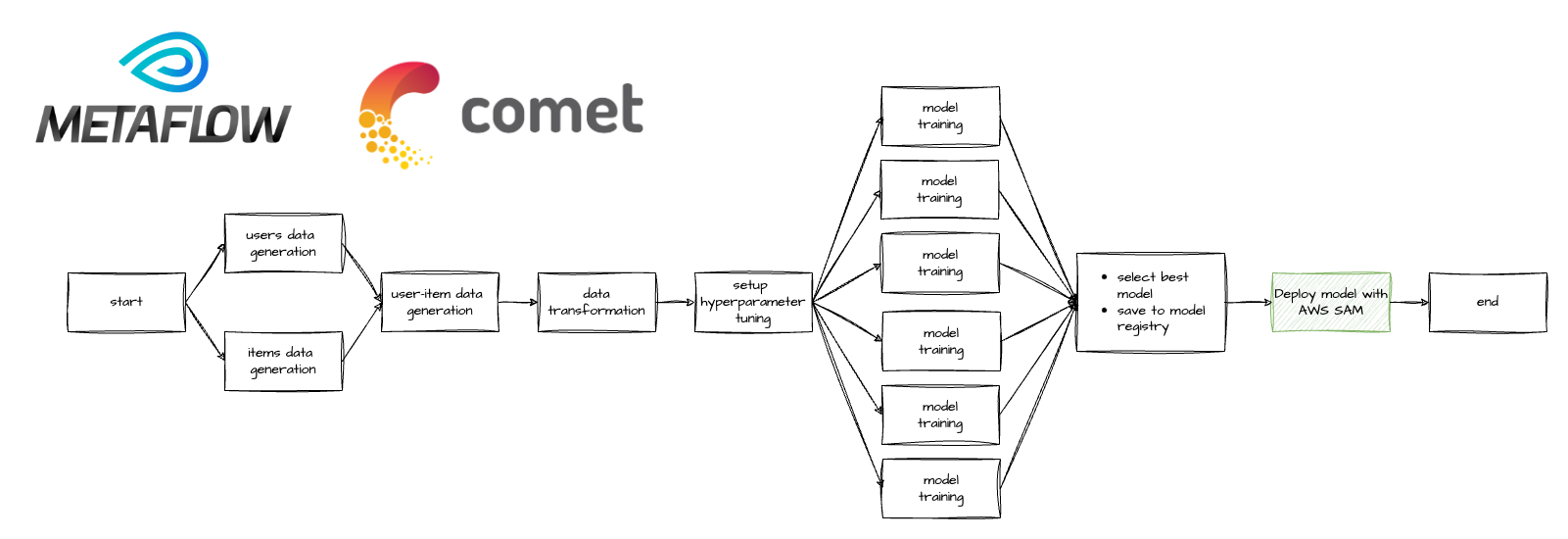
In part 1 of this series, we introduced how to build a recommender system (RecSys) using matrix factorization for implicit feedback systems. We implemented a simple MLOps workflow using third-party tools Metaflow and Comet, where we built up our RecSys through the parallel training of multiple models, tracking all experiment metrics, selecting the best model and finally pushing our best model to a model registry.
In this article, we will:
In part 1, after we trained the model, we performed a model evaluation to check the model’s correctness. That produced a metric that we can use to compare each build. We used Comet’s python SDK to log the model, which we have pickled in an S3 destination. Once the model is logged in the experiment (please see line 20 below), it will now be part of the experiment together with all the metadata that it is made of. Please see this Comet link to read more details on how to use the model registry.
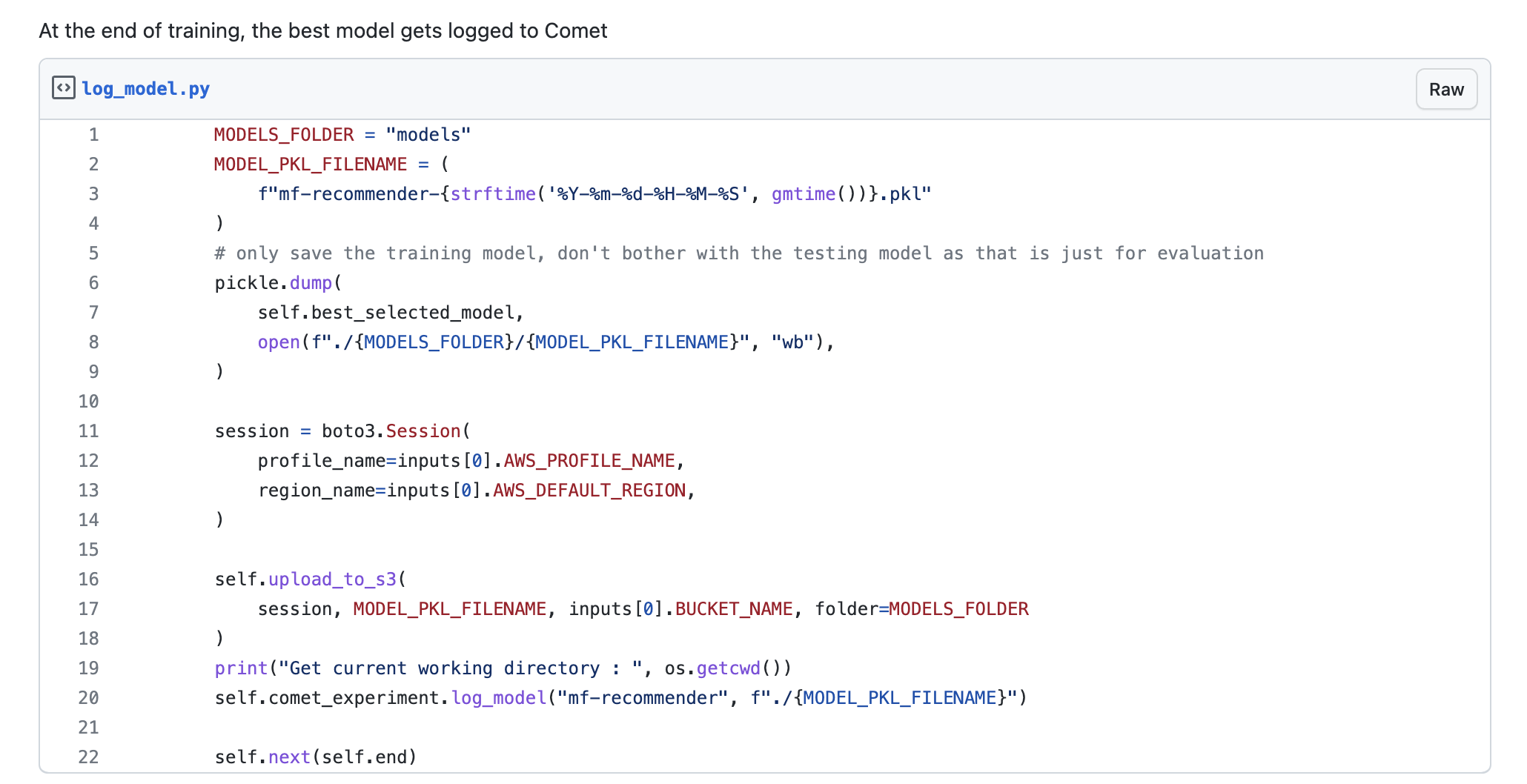
Once a model has been logged into an experiment, it can then be registered into the model registry so that it can be shared with your team. This will then be easier to track your models, retrieve the model binaries, either through the Comet web interface, or further integrated into your team’s MLOps automation through the python SDK.
I have decided to utilise AWS Lambda as our serverless solution for hosting our recommender system, opting to steer clear of managing servers, whether they are https://aws.amazon.com/ec2/ or docker containers in the cloud. Dealing with servers would be cumbersome for our small-scale system. While we could have taken the easy route and built our Lambda function and REST API using the AWS Console’s clickOps method, given the simplicity of our system, I wanted to challenge myself and delve into Infrastructure as Code (IAC), ensuring that our solution is maintained in source control.

Initially, I considered using Amplify, which had been successful for building our e-commerce application. However, configuring Amplify with single sign-on (SSO) posed some difficulties, prompting me to explore an alternative approach: the Serverless Application Model (SAM) – a framework for building serverless applications. I had been intrigued by SAM for some time, and now seemed like the perfect opportunity to give it a try.
To my surprise, SAM turned out to be open-source. I was impressed by its user-friendliness, a characteristic often found in well-supported open-source projects.
AWS Lambda is often a compelling choice for building serverless applications, thanks to the built-in conveniences that eliminate the need for setting up and managing servers. When working with Python, AWS Lambda provides a runtime environment that we can leverage in our recommender system. However, as we built the project, we encountered some challenges:
While Lambda offers an extensive list of Python modules, essential libraries like numpy, scikit-learn, and pandas, commonly used in machine learning systems (some of which we use here), are notably absent.
Furthermore, Lambda has an uncompressed size limit of 250MB for function packages. These missing libraries that we needed, such as numpy (108MB), scipy (156MB), and pandas (151MB), already exceed this limit. Considering we haven’t even accounted for the Implicit library yet, crucial for our matrix factorization recommender, the size constraints become even more restrictive.

Adding these external libraries as Lambda Layers is one option to bring them in. However, Lambdas are limited to five layers and exact size restrictions, which falls short of what we require for our recommender system.
At this point, it became evident that using Lambda Layers for our RecSys was not feasible. Luckily, AWS offers an alternative solution – Lambda Container Images!
By adopting Lambda Container Images, which currently has a container size limit of 10GB, we gain the flexibility to package our application and all necessary dependencies into a custom container image. This way, we can include all the required libraries and modules, which will easily fit our required Python dependencies without any Lambda layer limitations. Container-Based Lambdas open up new possibilities for deploying our recommender system with ease and efficiency.
And because container-based Lambdas are supported in SAM, we now have a potential solution to try out! So I built such a lambda based mainly on an AWS tutorial. However, we’ve immediately hit a snag.
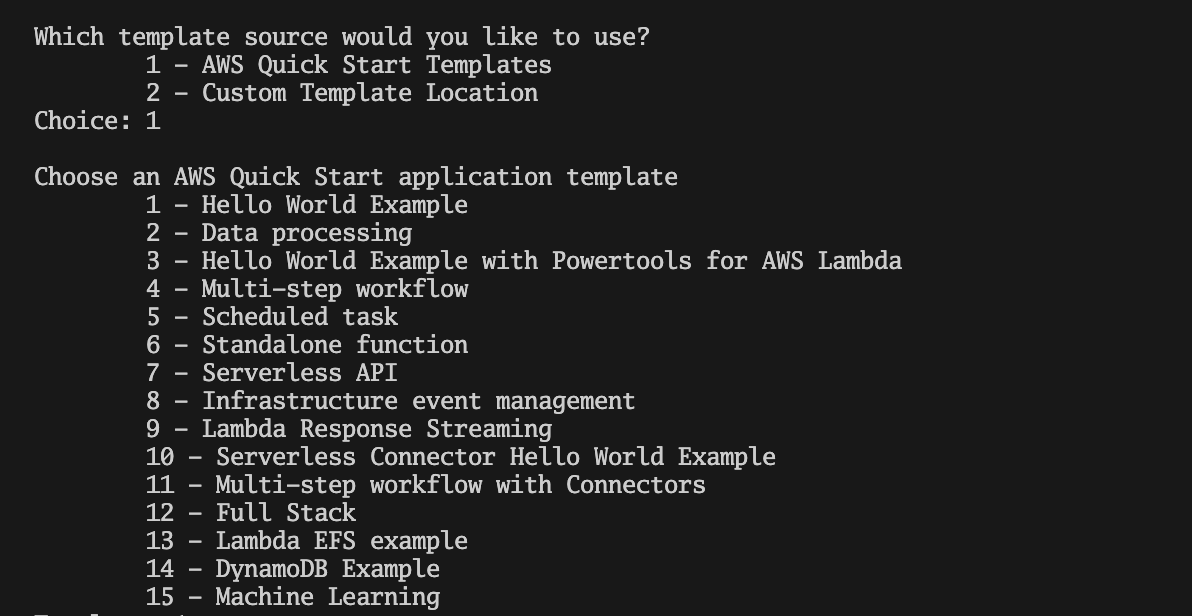
Upon running a get request with Postman, I got a runtime error:
ImportError: libgomp.so.1: cannot open shared object file: No such file or directory…
This error came from our import of Implicit Library, and it was not happy with the dependencies included in the Lambda image.
Asking the Cevo Hive Mind, I got my answer within a few minutes. All I needed to do was to yum install this dependency into our container, and that should resolve the error. And what do you know? It works! See line 4 in the Dockerfile below:
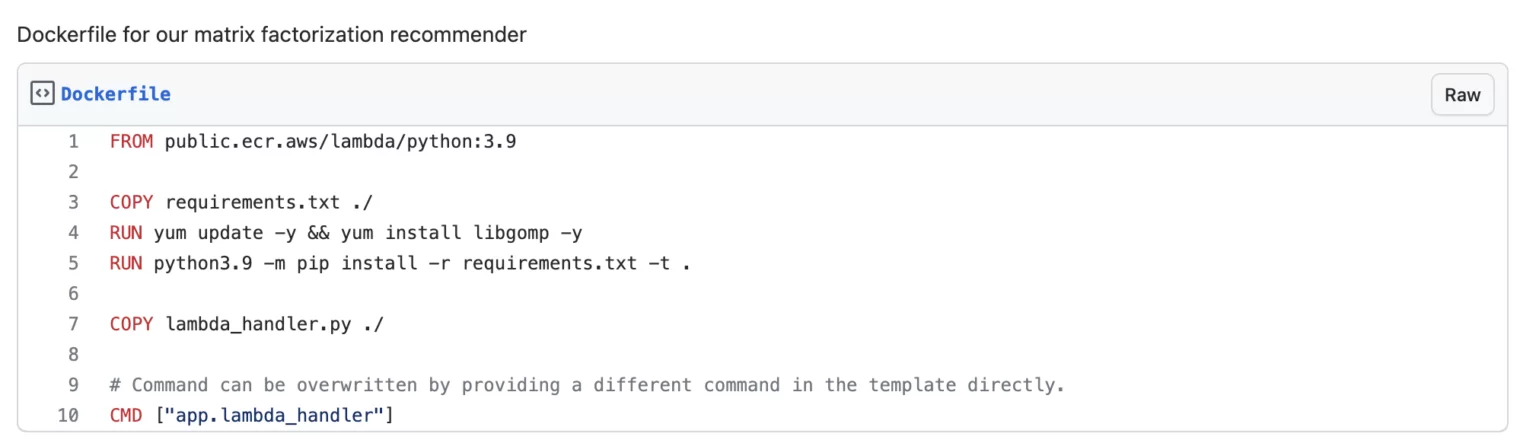
Now that we have successfully built our Lambda using SAM, it’s time to integrate it into our MLOps workflow. To achieve this, we revisit our Metaflow script and pinpoint the exact moment in the flow where we need to invoke SAM to deploy the model with the highest MAP@K score, as determined during the model evaluation.
Before proceeding further, we must locate the winning model’s file and path. This information is crucial as we will use SAM to deploy this model onto our Lambda, making it accessible through a REST API. Fortunately, we can leverage Metaflow’s global variables, particularly the ‘self’ variable, along with dynamic parameters passed to SAM during stack deployment to accomplish this task. Line 12 below shows how to invoke SAM from a Metaflow script and pass the Lambda environment variable.
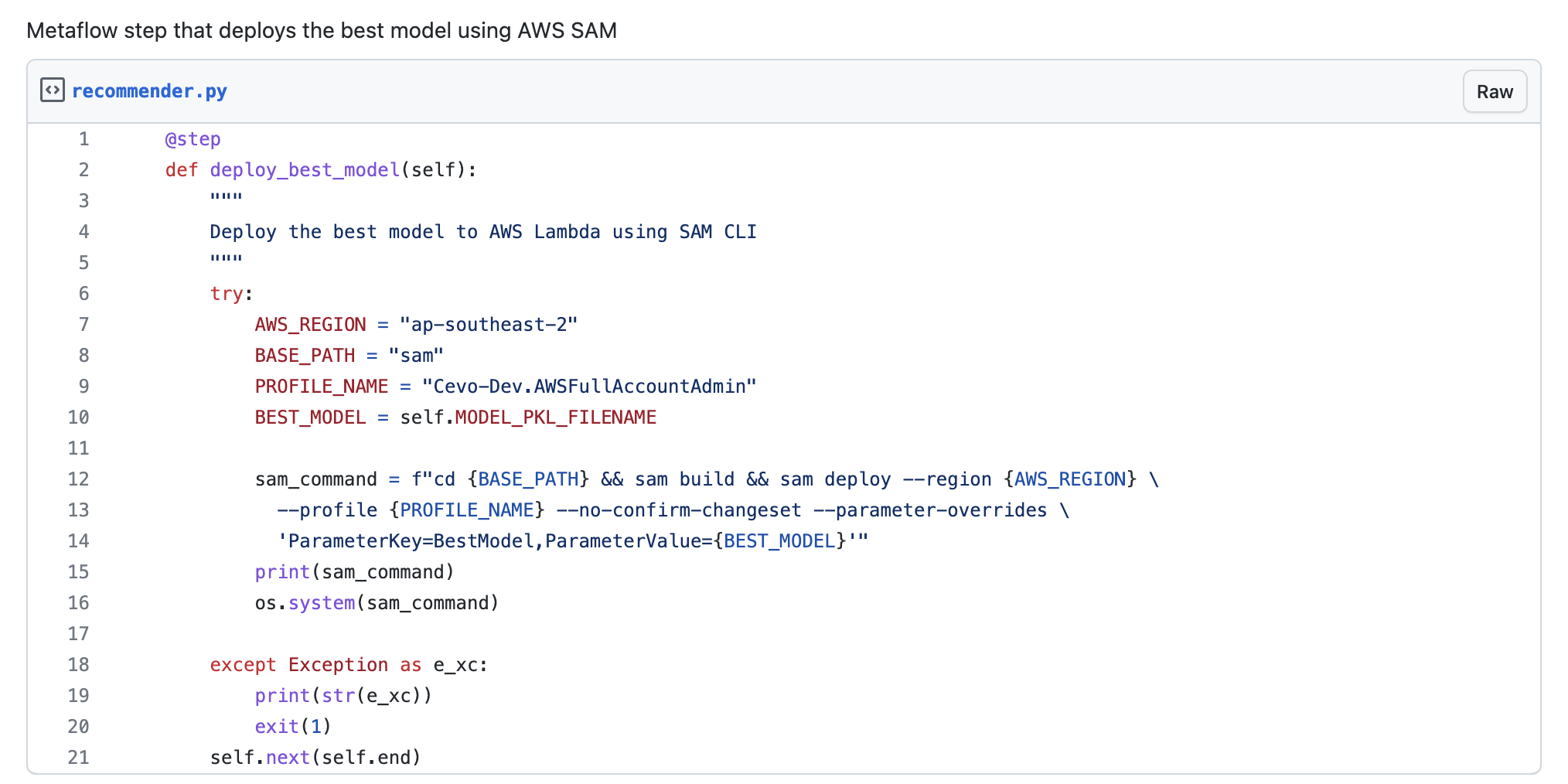
Once we have obtained the path and location of our best model (we can also check the model registry for this information), the next step is to set our Lambda’s environment variable as described above, ensuring it’s readily available when the Lambda requires it. With these preparations complete, we can run our updated Metaflow script, which will run everything, including seamlessly deploying the best model onto AWS! Our next milestone is integrating this model with our front end, bringing us one step closer to achieving our mission of replacing AWS Personalize with our custom solution.
At last, we have concluded our experiment’s culmination in building our very own recommender system. Looking back, it has been quite a journey. We began by acquainting ourselves with recommender systems, taking our first steps with Amazon Personalize. In the prequel, we even crafted a sample e-commerce web application to test it out. This initial experience provided a smooth entry into recommender systems, but we craved more.
In Part 1, we decided to delve deeper and experiment with building our system. We opted for a simple matrix factorization method, a simple embedding method, which, while not cutting-edge, offered valuable insight into how popular sites tackle this challenge.
In this final instalment, Part 2, we took the model we constructed in Part 1 and deployed it to a serverless infrastructure on AWS, using the open-source Serverless Application Model. This final leg of the journey brought us full circle as we integrated our recommender system into the original e-commerce web application we built in the first article.
If you want to go and look back at the articles and source code for the whole series, here are some handy links:
Build Recommender Systems the Easy Way in AWS
How to Build, Train and Deploy Your Own Recommender System – Part 1
How to Build, Train and Deploy Your Own Recommender System – Part 2
Note: This article was originally published on Cevo Australia’s website
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.