How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


Before I first started working with DynamoDB, I thought that working with NoSQL databases like DynamoDB is easy, similar to any relational database I’m used to. I realized that DynamoDB is different, and there is a steep learning curve involved.
To reap all the benefits of DynamoDB, you have to use it how Amazon intended - using as few tables as possible, ideally a single table per application, instead of the usual one-table-per-entity method that we have been doing with RDBMS all these time.
As a general rule, you should maintain as few tables as possible in a DynamoDB application. - AWS DynamoDB Developer Guide
Follow along as I implement the Single-Table method from scratch, find out the framework and tools I used to make the process easier, and finally the light-bulb moment when it all made sense!
Many developers familiar with databases will approach DynamoDB in a similar way to developing with relational databases - i.e., normalize all data, keep each entity in it’s own table, and join table data at the point of query. This is well and good for relational databases, however we cannot continue this way with DynamoDB because it does not have joins like what SQL has.
The process of joining tables is an expensive operation. It takes a lot more CPU cycles to gather related data from separate tables, than if all the related data can be retrieved with a single request. This is the approach that NoSQL databases have adopted, instead of trying to make joins faster, it avoids the problem completely by dropping support for it.
 Figure 1: Multiple-Table Design in DynamoDB will result in unnecessary multiple network requests (Copyright, The DynamoDB Book)
Figure 1: Multiple-Table Design in DynamoDB will result in unnecessary multiple network requests (Copyright, The DynamoDB Book)
Even with this limitation, it hasn’t stopped many developers from persevering with multiple table design, and end up joining the data at the application itself - without realizing the implication of that decision. This will result to higher costs since the application will need to make multiple network requests to the database. It will still work, but with more requests to the database than needed. Moreover, as the application scales, it keeps getting slower and slower, and more expensive to run.
In the end, they will hate DynamoDB because it is SLOW and EXPENSIVE, disgruntled that DynamoDB did not keep its promise of single digit millisecond latency.
If only they invested the time to learn how to use this technology correctly, I’m sure the end result would have been totally different.
Amazon intended developers to use as few tables as possible, ideally one table per application. In Computer Science, study on cache operations will mention locality of reference - this is defined the single most important factor in speeding up response time.
This also translates well to NoSQL databases - so keeping related data together has a major impact to cost and performance. Instead of spreading your entities across multiple tables, you should strive to keep it in one table to enable you to get all those related data with a single request.
Instead of reshaping data when a query is processed (as an RDBMS system does), a NoSQL database organizes data so that its shape in the database corresponds with what will be queried. This is a key factor in increasing speed and scalability. - AWS DynamoDB Developer Guide
This is the promise of single table design - avoiding the costly join operation and take advantage of the cost and speed efficiency of getting all heterogenous related items with that single request.
 Figure 2: Single-Table Design in DynamoDB will result in more efficient requests (Copyright, The DynamoDB Book)
Figure 2: Single-Table Design in DynamoDB will result in more efficient requests (Copyright, The DynamoDB Book)
Only after having read articles by AWS Data Hero Alex DeBrie and watching a video by AWS NoSQL Blackbelt Team Lead Rick Houlihan did it occur to me that there is more to DynamoDB than I initially thought. That to make sure that DynamoDB scales, remains performant and cost effective, one must listen and learn from the knowledge of the experts.
So in this article, we will walk through a simple project and approach it how you would when starting a typical DynamoDB-based application.
The following tools and libraries were used:
NoSQL Workbench - AWS recently released (GA on 2 March 2020) an application for learning and working with DynamoDB. This tool helps you create your entities and was responsible for that light bulb moment when I visualized my models and item collections with its Aggregate View feature.
AWS-SDK - Node.js version of the AWS SDK that allows access to DynamoDB features among other things.
AWS Lambda - AWS Lambda is Amazon’s serverless offering, which is a simple way to host serverless functionality using Amazon’s tried and tested infrastructure.
Serverless - easily handle the deployment our Lambda using this popular infrastructure-as-code product.
NodeJS - it’s all Javascript for this project, no front-end (we’ll tackle that in a separate article), so we’ve picked NodeJS for its simplicity.
The application is called F1 DynamoDB a NodeJS API which returns Formula 1 racing related data and results. It is a subset of a project that I would like to eventually complete. If only I don’t get distracted by the many interesting bits in technology! It is also fitting to host it in AWS Lambda, DynamoDB is best used for serverless applications after all.
Did you think that we have left Entity Relationship Diagram in the realm of RDBMS? No! ERDs are still quite useful when dealing with NoSQL databases, as we are still trying to show the relationship between entities, even when these are all co-located in the single table.
 Figure 3: Entity Relationship Diagram for F1 DynamoDB project
Figure 3: Entity Relationship Diagram for F1 DynamoDB project
One of the main differences with developing with DynamoDB is you have to know your access patterns up front. This was hard for me to get my head around as I started tinkering with DynamoDB. Normally, we don’t give much thought about this with SQL, which steers us towards a general-purpose database, at the expense of scalability.
DynamoDB will not allow you to create slow queries, defining the query patterns up-front is the compromise. Ensuring you create a scalable database, at the expense of general purpose utility.
For our simple app, we want to support the following:
Get all Formula 1 seasons
Get all races for a given season
Get all race results for a given race
With single-table design, because we are storing multiple entity types in the same table, we typically overload the primary key and sort keys. We normally use generic names for these keys like PK and SK.
| Entity | PK | SK |
|---|---|---|
| Season | SEASON#<season> | SEASON#<season> |
| Race | SEASON#<season> | RACE#<round> |
| Result | SEASON#<season> | RACE#<round>#RESULT#<rank> |
Unlike in multiple-table design where you can be more descriptive of your primary key and sort key names to reflect more closely what items the table contains.
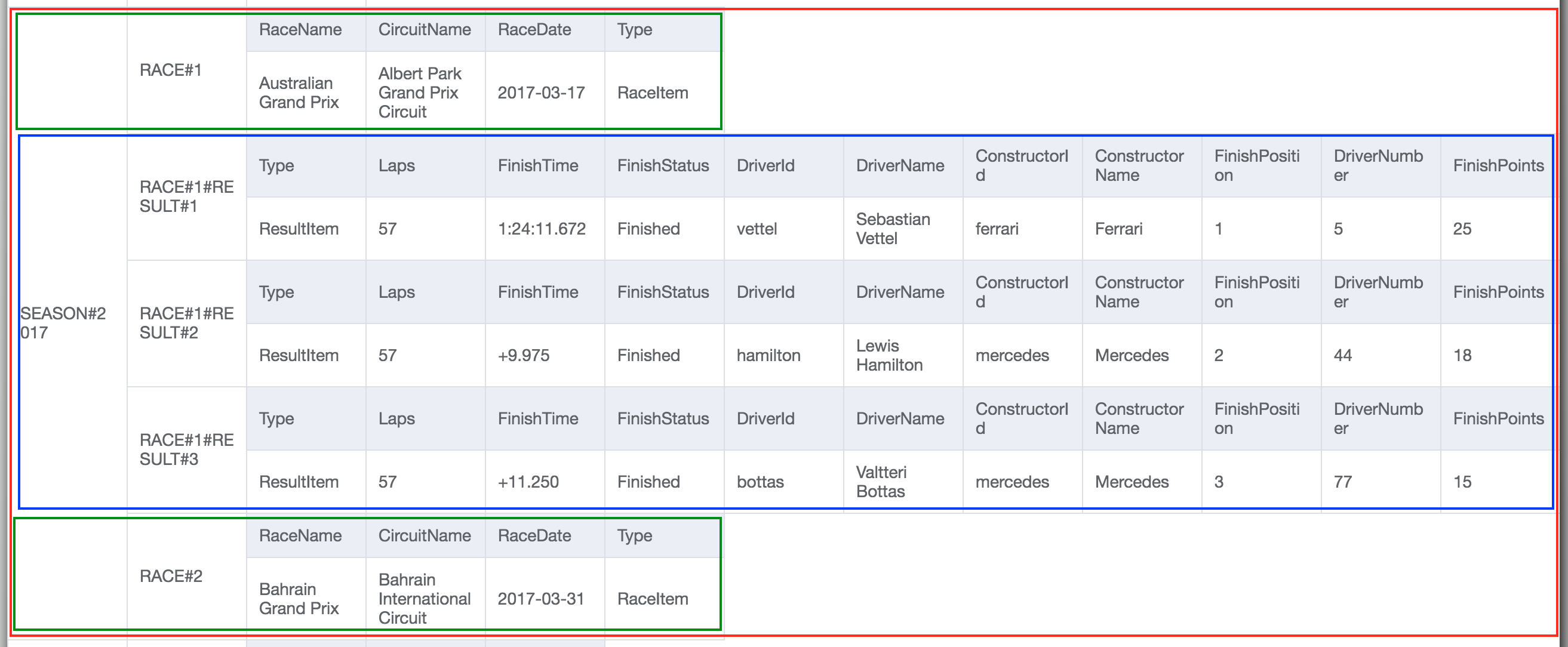
And here is a screenshot of NoSQL Workbench visualizing in Red the Season item collection, containing both RaceItem(Green) and ResultItem(Blue) data. These related race data can be requested in a single request, simulating the join-like behavior in RDBMS, and this is when the penny dropped for me!
OK, now this is when we start looking at some real code! First of all, I have F1 DynamoDB in Github, so if you want to, clone this repo and do anything that you want with it! Source code has been adapted from The DynamoDB Book, props to Alex for creating an excellent DynamoDB resource.
The very first thing is to add Serverless setup in serverless.yml file. I am a proponent of infrastructure-as-code and Serverless enables us to do this easily.
Our Serverless configuration does the following noteworthy items:
 Figure 5: Output of the Serverless DynamoDB deployment
Figure 5: Output of the Serverless DynamoDB deployment
And in the file package.json, the deploy script will deploy to AWS from VSCode, while debug will run the API locally for development and debugging purposes.
 Figure 6: Output of the Serverless offline for local development
Figure 6: Output of the Serverless offline for local development
Based on our ERD we have 3 entities - seasons, races, and results. This corresponds to our 3 entities in our application. Seasons, Races and Results.
Each Entity will also have a data access code to talk to DynamoDB using AWS-SDK - Seasons, Races and Results.
Finally we define our lambda handlers to enable the functionality to be exposed to the world. Following the previous pattern, we also have one handler for each entity - Season, Races and Results.
I have loaded a minimal data set for the API so that we can quickly invoke our new serverless functions. Ideally we will need some ETL process or some scripting to load the database with our seed data. I have created a sample Python script that can be used for this purpose. The following are the 3 queries created by the preceding steps:
 Figure 7: Lambda API Formula 1 Results using Postman
Figure 7: Lambda API Formula 1 Results using Postman
We covered a bit of ground with our DynamoDB learnings in this article. DynamoDB plays a very important role inside Amazon where they have migrated hundreds of mission critical and thousands of secondary services.
However, it still gets mixed reviews from the developer community. It is important to understand that in adopting a new technology like DynamoDB, one should learn how to use it the correct way before applying it in production.
Developers who are experts in RDBMS technology by default apply that same method to DynamoDB, but that just does not work. They find that as they scale, their application becomes slower and slower, or more expensive to run, or both.
We were introduced to the single-table method - the recommended (yet lesser known) way to model data in DynamoDB. DynamoDB promises single-digit millisecond latency, however to achieve this, one should be ready to accept the compromises.
If DynamoDB is good enough for Amazon, it’s good enough for me too.
These picks are things that have had a positive impact to me in recent weeks:
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.