How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


AWS provides users with the flexibility to build machine learning (ML) applications from scratch, but they also offer various high-level AI services that allow consumers to leverage the power of machine learning without any prior knowledge of the subject.
In this article, we will explore the fascinating world of recommender systems. As this is our first foray into this topic, let’s use an AWS service to speed up our ability to add recommendations into our product.
This AWS service is called Amazon Personalize - a fully managed and scalable AI service that simplifies the ability to add personalisation into your product. In fact, in this article, we will be adding recommendations to an existing e-commerce application, so we can see what is involved in this process. Towards the end of the article, we will also be doing a quick cost / benefit analysis to understand the upsides it can contribute to your business.
However, before we dive into Amazon Personalize, let’s take a step back and get a deeper understanding of the what, why and how of recommender systems.
A recommender system (also called RecSys) is a sophisticated information filtering system that leverages user preferences, interests, and behaviours to provide personalised recommendations. It helps improve sales conversion and user retention by assisting customers find catalogue items they like but won’t organically find, based on content they have already shown interest in.
Recommender systems are valuable because they help users discover products, services, or content that they may not have otherwise found on their own. These systems use data analysis techniques to make predictions or suggestions based on several factors depending on the technique used. By providing personalised recommendations, these systems can improve user engagement and satisfaction, increase customer loyalty, and drive sales. Let’s look at how we identify relevant items through filtering.
Recommender systems utilise various techniques, including content-based filtering, collaborative filtering, and hybrid filtering. Content-based filtering makes use of item attributes to recommend items that are similar to the ones the user has previously liked, answering questions like “What items have I liked in the past, as I might enjoy similar items like that?”
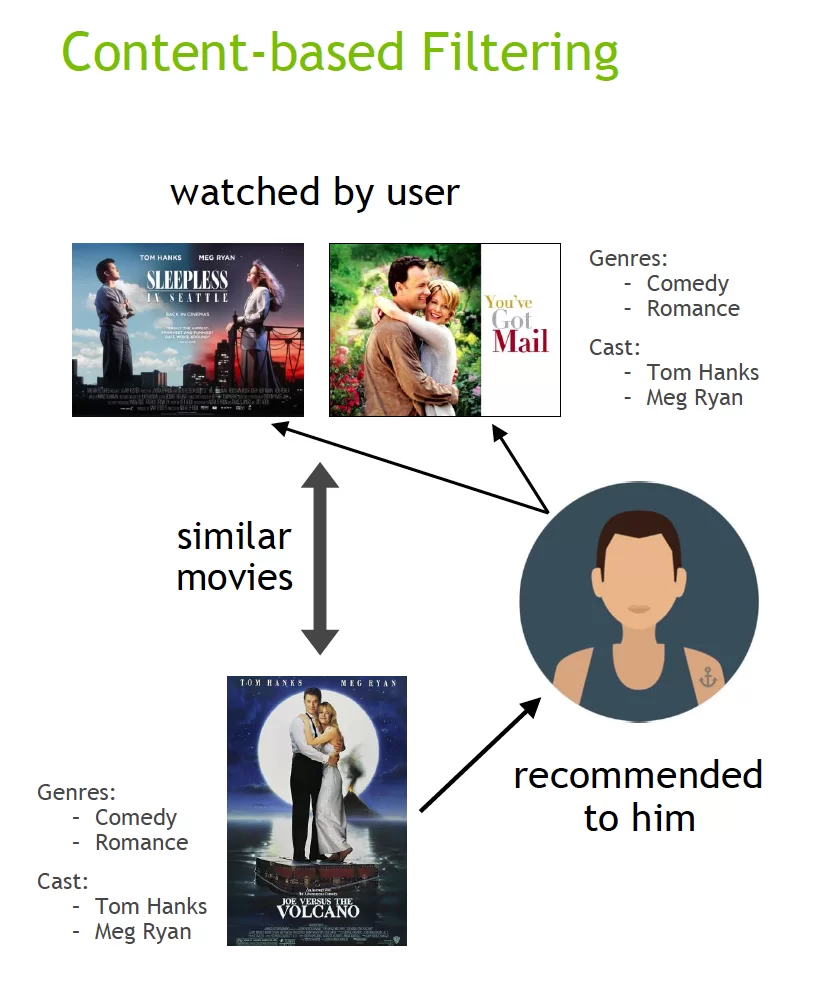
On the other hand, collaborative filtering analyses user behaviour and identifies users with similar preferences, answering questions like “What do users similar to me like, as I might like these items too?”
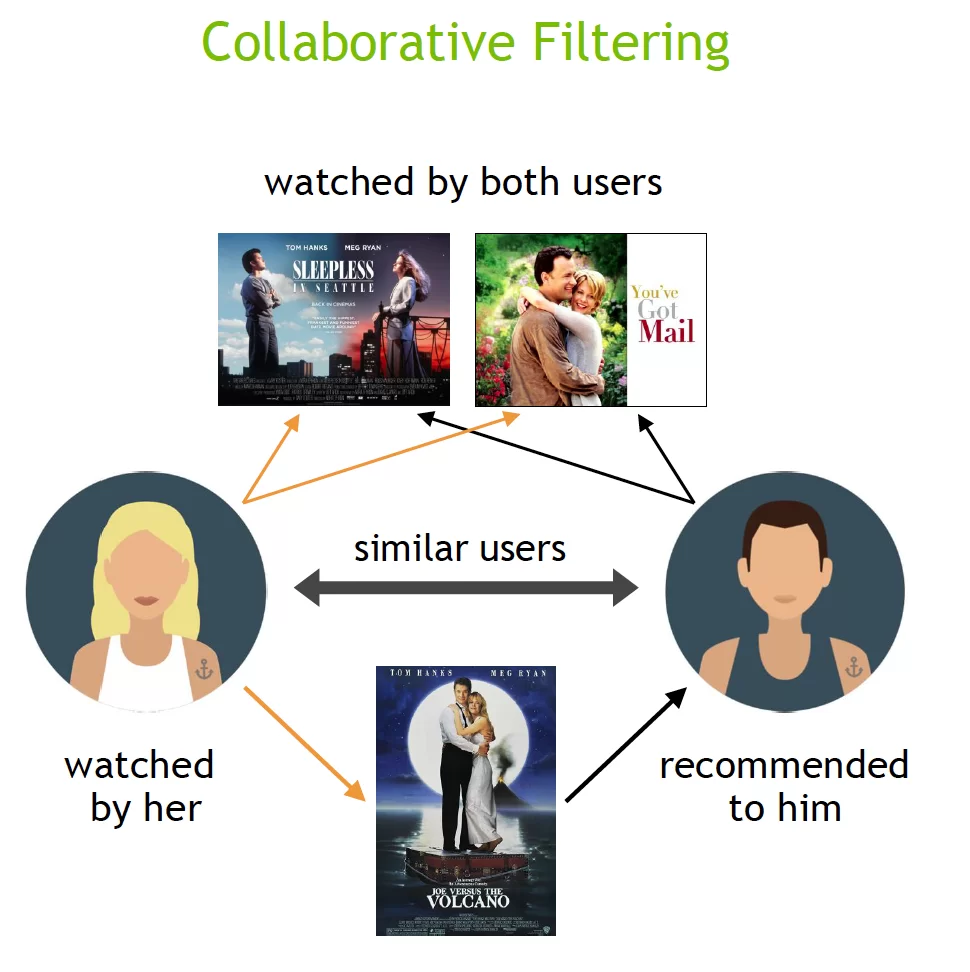
Hybrid filtering combines both approaches to provide more accurate and comprehensive recommendations, taking advantage of the strengths of each method.
Recommender systems are ubiquitous and are widely employed in e-commerce, online advertising, social media, and entertainment industries to enhance customer satisfaction, boost sales, and improve engagement. They are a valuable tool for businesses to offer personalised experiences to their users, leading to increased user engagement and loyalty.
Amazon Personalize, a ready-to-use AI service, is a recommender system that uses your data to generate item recommendations for your users. Amazon makes it easy by providing a system where you don’t even need to know much about machine learning; just feed it a user, an item and user-item interaction data, and you will be serving recommendations in your project in no time.
There are multiple challenges to building and maintaining a bespoke recommender system.
Coverage - With an ever increasing catalogue of items, user base and interactions, it’s a challenge to maintain a model that can handle all that with low latency.
Adaptability - Keeping data up to date is a challenge. In this case, the users, items and interactions data will need to be up to date using data pipelines that you will have to build and maintain yourself. The ability to ingest data in real time or through a batch process will need to be supported too. The system will need periodic training of the ML model as the data changes.
Cold starts - The ML model has to handle user and item cold starts well. User cold start is when the logged-in user has just been added to the system, while item cold start is when a new product is added to it. In both these cases, they do not yet have any interaction history from which to draw the recommendations from.
Scalability - The system should be able to scale to millions of users and products, each with their own list of interests and properties.
User preferences - The system should be able to handle changing trends and preferences for the number of users in the system.
Evaluation - A recommender system is not an install-and-forget system. They should be periodically evaluated with known metrics and retrained when model drift has been detected.
Many satisfied customers have leveraged the power of Amazon Personalize to elevate their product offerings through effective personalisation strategies. Here are just a few:
![]()
Warner Bros. Discovery, a premier global media and entertainment company, offers audiences the world’s most differentiated and complete portfolio of content, brands and franchises across television, film, streaming and gaming.
“Our team at Warner Bros. Discovery wanted to build a promotion engine to customize movie and show recommendations for unauthenticated users across our digital properties. We wanted to drive cross brand engagement as users traverse the brands and content across the WBD ecosystem. With Amazon Personalize we were able to build and train a real-time recommendation engine POC within two days. Since deployment on our TBS, TNT, TruTV and Adult Swim web properties, over 25k unique consumers have clicked on cross-portfolio promotions for the movies, shows and site sections recommended by Amazon Personalize. These promising results have paved the way for us to deploy our promo engine on CNN next month. For the users receiving personalized promotions we have seen total user engagement increase by 14% and cross brand engagement increase by 12% compared to a randomized control group. We have also observed a 2x to 3x increase in response rate using personalized promotions vs. simply promoting our most popular items to consumers. Amazon Personalize has been instrumental in showcasing content that our fans want to see more effectively across our various brands.” - Don Browning, VP Cloud Architecture, WBD

Lotte Mart is a subsidiary of Lotte Conglomerate, the leading retail company in Korea. It operates hypermarket, members-only warehouse discount outlets, electronics digital shops, and toysRus stores in Korea. It has 187 stores in Korea, Indonesia and Vietnam.
“By using Amazon Personalize, we have seen a 5x increase in response to recommended products compared to our prior big data analytics solution resulting in increased revenue per month. In particular, Amazon Personalize has increased the number of products that the customer has never purchased before up to 40%. The new recommendation service powered by AWS is the first of a much broader roll-out of AI technologies across our organization.” - Jaehyun Shin, Big Data Team Leader, Lotte Mart
![]()
Intuit is a business and financial software company that develops and sells financial, accounting and tax preparation software and related services for small businesses, accountants and individuals.
“With Amazon Personalize, we were able to quickly design and launch a recommendation engine for Intuit’s Mint budget tracker and planner app. Using customer profile and behavioral data, with machine learning, the service helps deliver the right financial offer to the right customer at the right time, based on their spending habits, lifestyle, and goals.” - Qiang Zhu, Director of Data Science, Intuit
Please see more Amazon Personalize customer successes here.
The more user, item and user-item interaction data in your dataset, the better the recommendations that are returned by the system. As a guideline, for all use cases (domain dataset groups) and custom recipes, your interactions data must have the following:
A minimum of 1000 interactions records from users interacting with items in your catalogue. These interactions can be from bulk imports, or streamed events, or both. A minimum of 25 unique user IDs with at least two interactions for each. For quality recommendations, we recommend that you have at least 50,000 interactions from at least 1,000 users with two or more interactions each.
One of the more common use cases for Amazon Personalize is to add a recommender to an already existing e-commerce application. It is a win-win situation for both the buyer and the seller; with effective recommendations, buyers will be delighted to use the application since the results are in sync to their preferences resulting in improved user engagement. Sellers on the other hand, will benefit with more clicks, better conversion and ultimately more profit.
For the e-commerce domain, we have a selection of built-in Personalize use cases to choose from, including: Customers who viewed X also viewed - Get recommendations for items that customers also viewed based on an item you specify. Frequently bought together - Get recommendations for items that customers frequently buy together along with an item you specify. Best sellers - Get recommendations for popular items based on how many times your customers purchased an item. Most viewed (Will be implemented in this article) - Get recommendations for popular items based on how many times your customers viewed an item. Recommended for you (Will be implemented in this article) - Get personalised recommendations for items based on a user you specify.
So, follow along in the next section to find out what is involved in creating recommenders for Most viewed and Recommended for you use cases and integrating them into an existing e-commerce application.
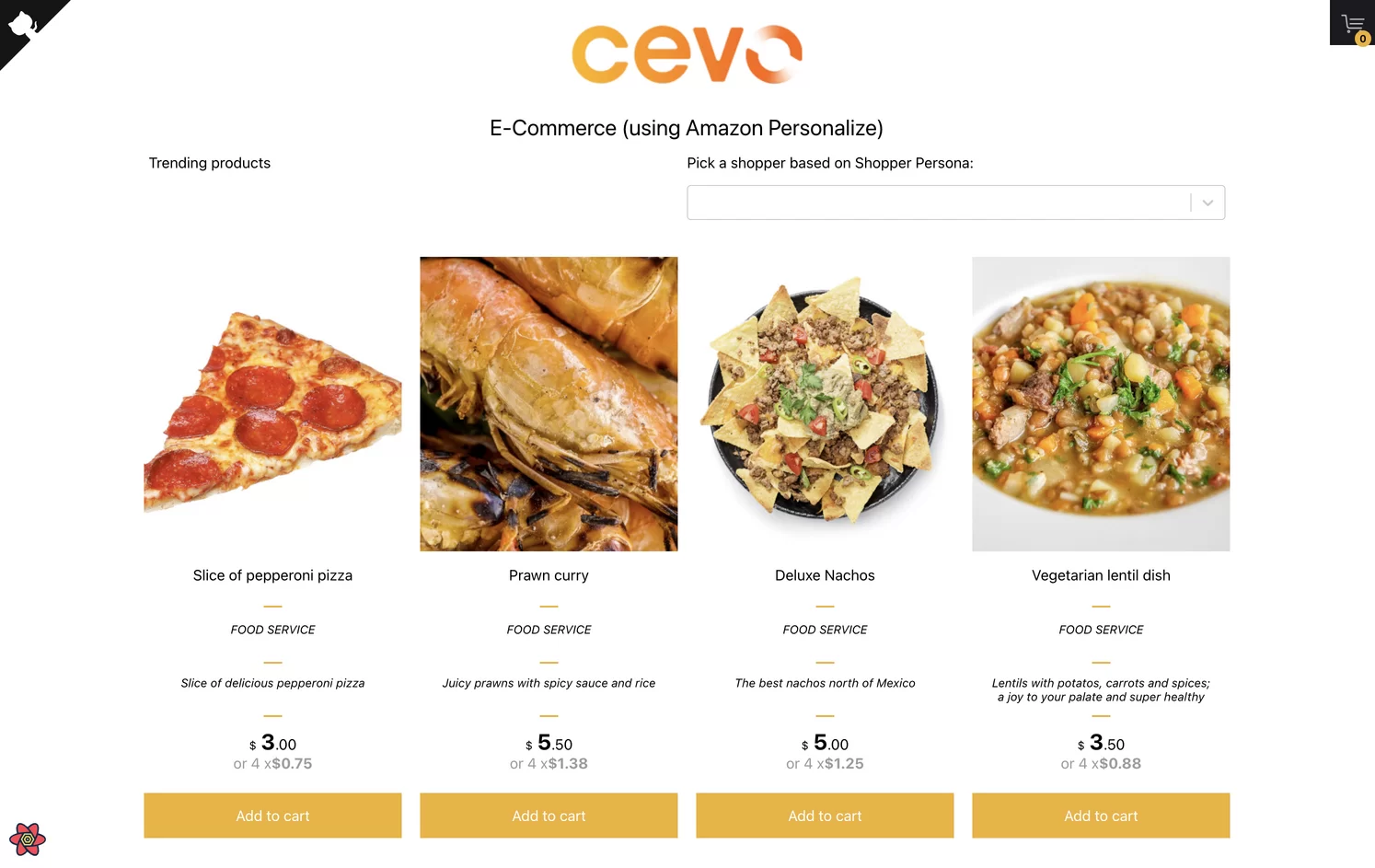
For this article, I have created an e-commerce application so that we can have a project to apply recommendations with. Here is the GitHub repo for the project. The main page returns a list of products ranked in order of recommendation.
For users who are not logged in, or have logged in for the first time, there is no user-item interaction history, so this list of products represents the most popular products in the system. For all returning and logged-in users, it should return the recommended items based on the user and item history.
When working with machine learning in the AWS ecosystem, everything revolves around the S3 bucket. It is no different with high level AI services like Personalize where the following scripts 01-prepare-users.py, 02-prepare-items.py and 03-prepare-interactions.py generate synthetic users, items and interactions data, in the form of csv files, and dump them into a known location in S3.
In this e-commerce application, we have created 2,465 items or products, 6,000 users, and 675,000 user-item interactions.
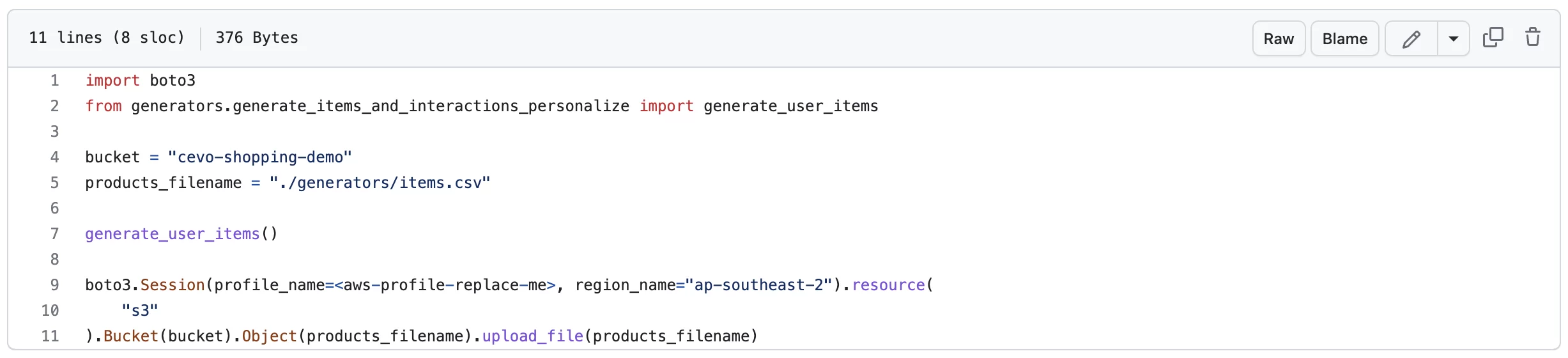
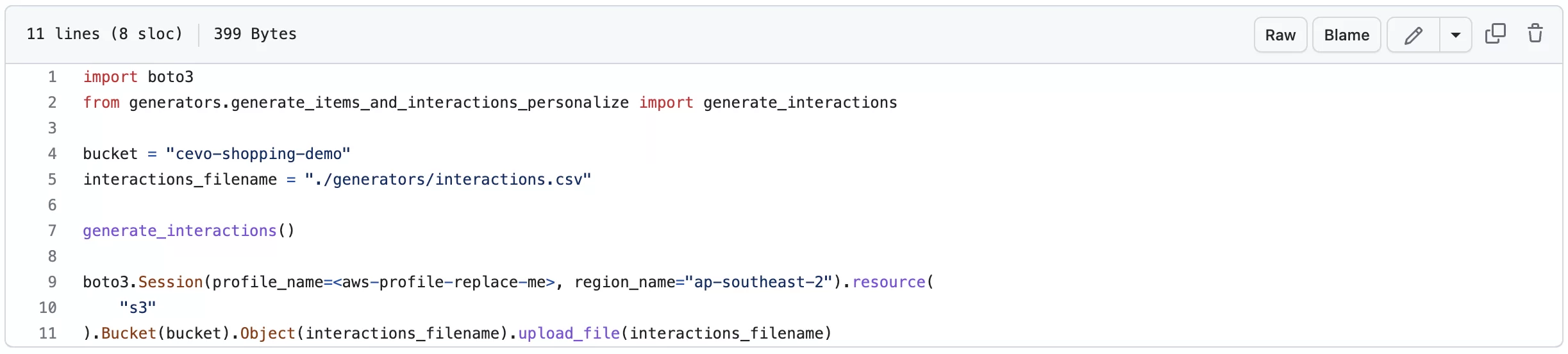
Although these steps can all be done from the AWS console, I have done all these from python scripts so that they are easier to repeat, and so that you can easily add them to your CI/CD system, if needed.
This is the script for this step: 04-prepare-dataset-group.py, where it creates items, user and interactions schema, in preparation for the creation of the recommenders in the next step. This is responsible for making Personalize understand the contents of the dataset we have just dumped into S3.
Now that the dataset’s schema has been created, it can now be imported into Personalize to get it ready for the training stage when the recommenders are created in the next step.

Once the datasets have been imported and ready for the creation of recommenders, the dataset import can then commence. Once completed, the datasets will show a green tick and status as active, like in the next image:
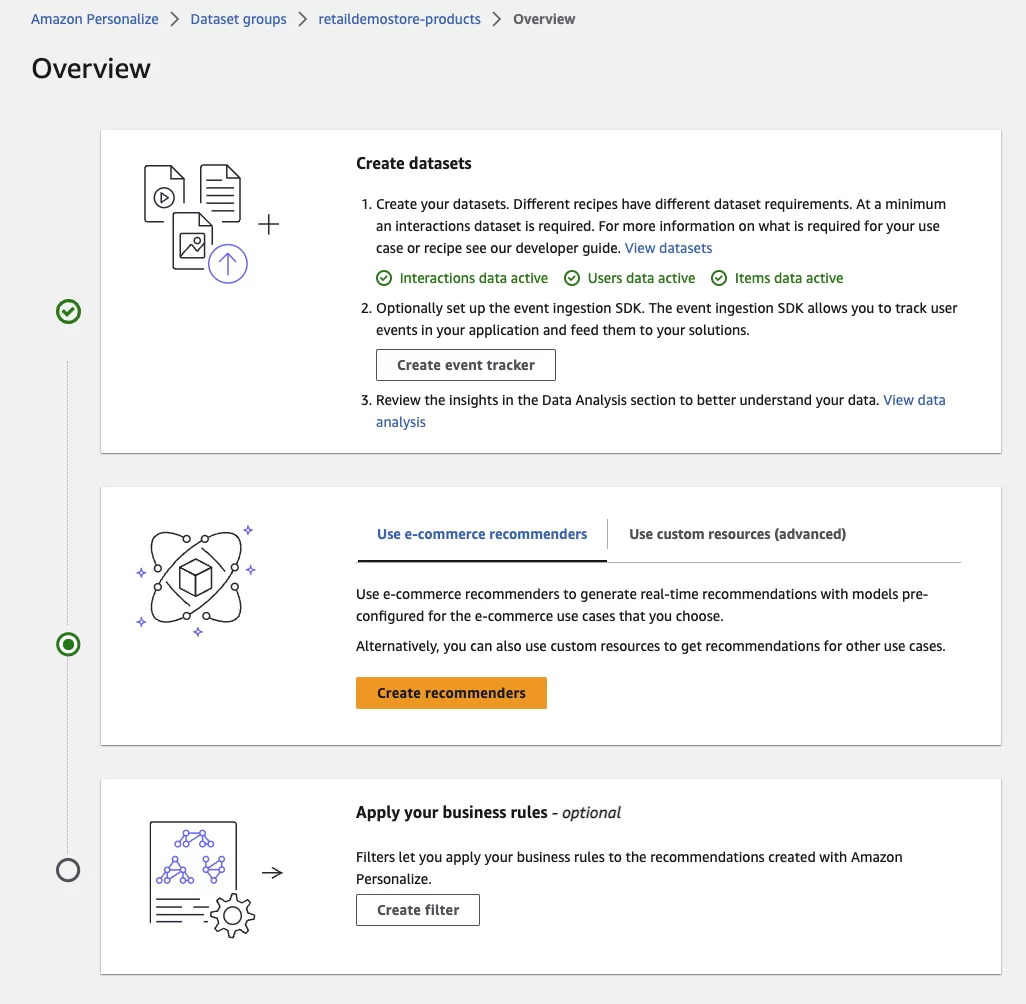
At this point, we can now create the recommenders, this is when the training happens, and this is done on the dataset that we have submitted to the item, user and interaction dataset group. Note that training time depends on the size of the datasets. In our example, training time takes about an hour.

We have just created two recommenders:
popular-items recommender, which returns recommendations for the most popular items, and recommended-for-you recommender, which returns predictions for a particular user
The python script below allows us to quickly test the recommended-for-you recommender. In line 15, we call the get_recommendations method of the Personalize runtime, passing the ARN for the recommended-for-you recommender, which is a parameter we stored in System Manager Parameter Store. We also pass the userId of the user we want to get the recommendations for. Finally, we specify the number of results we would like it to return.
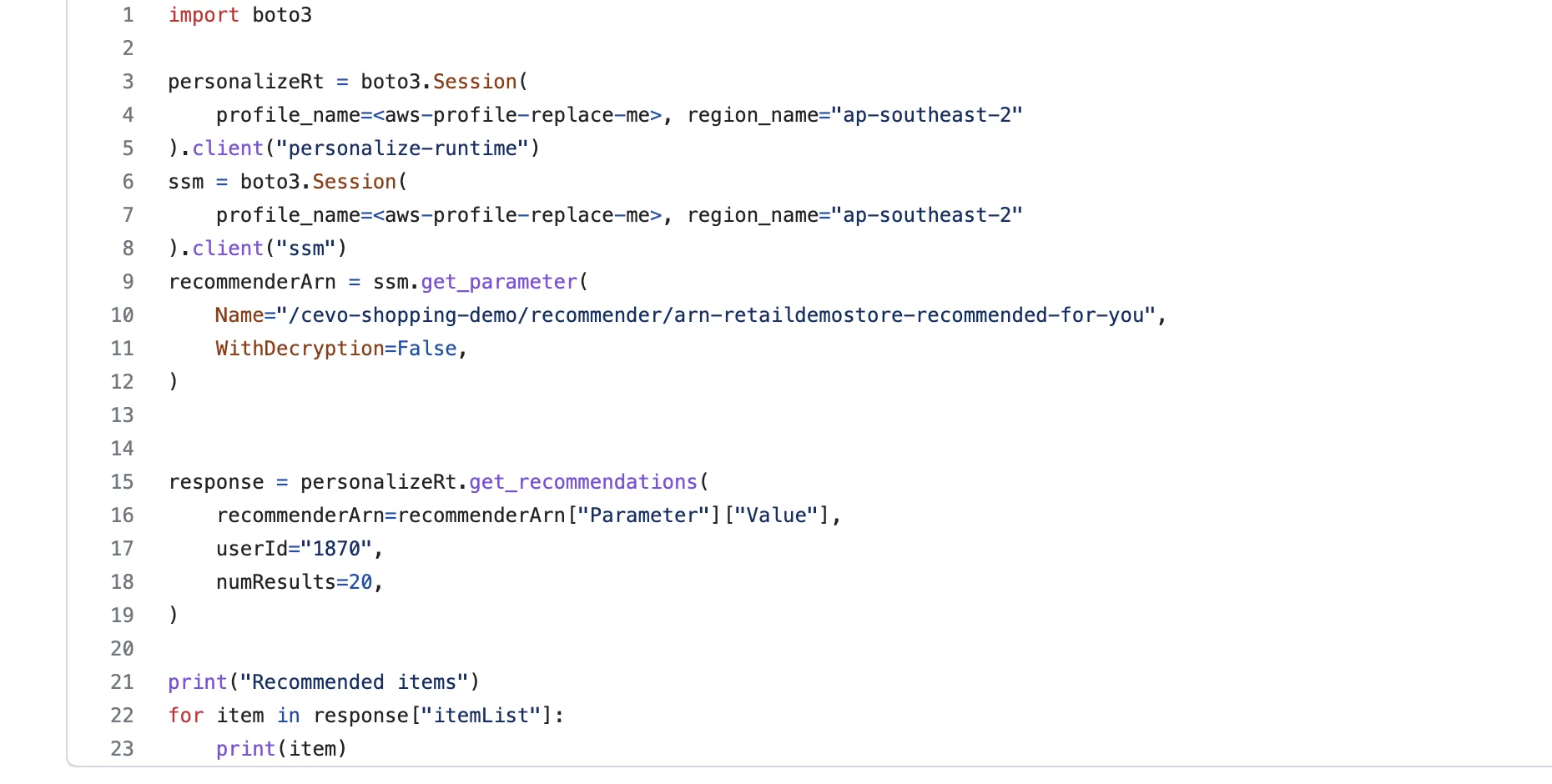
In our python backend, I have added boto3 calls to the recommenders that we have just created. In the function get_recommended_items, we are calling get_recommendations against the recommended-for-you recommender to return the recommended items for the specified user.
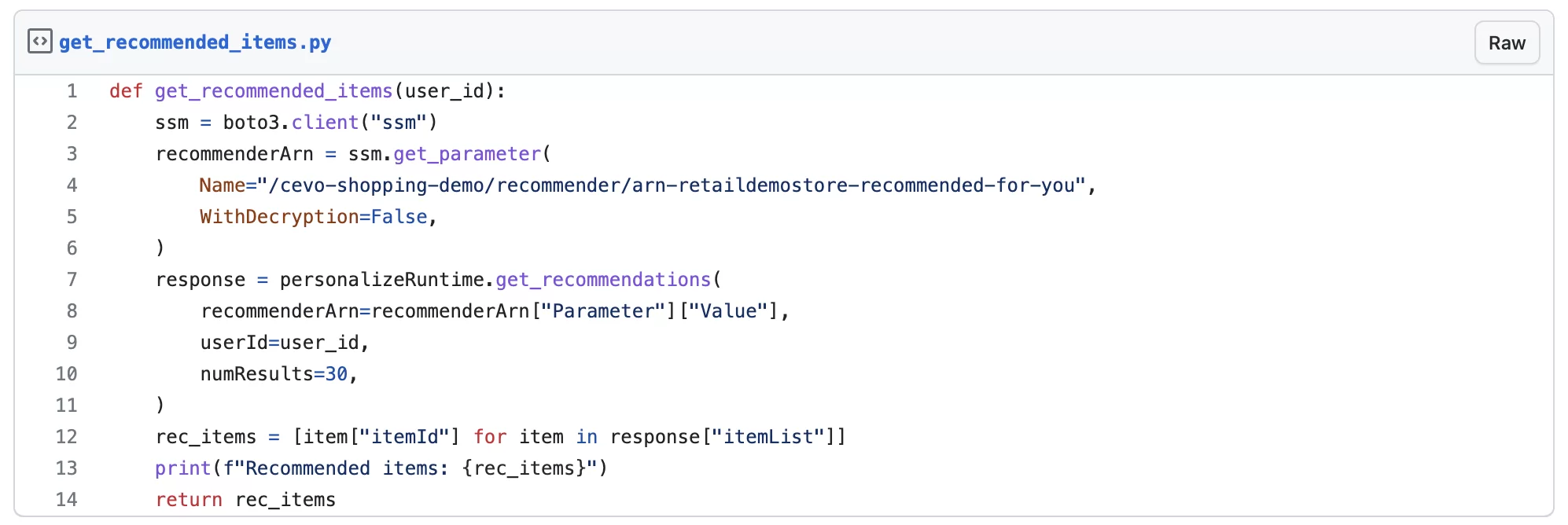
The python function get_popular_items uses the get_recommendations API call against the popular-items recommender to return popular items, notice that we are passing dummy user id ‘x’, so the call is not really for any particular user.

To wire the API call with the frontend, we simply pass the saved user id to the API call, and simply return the response.
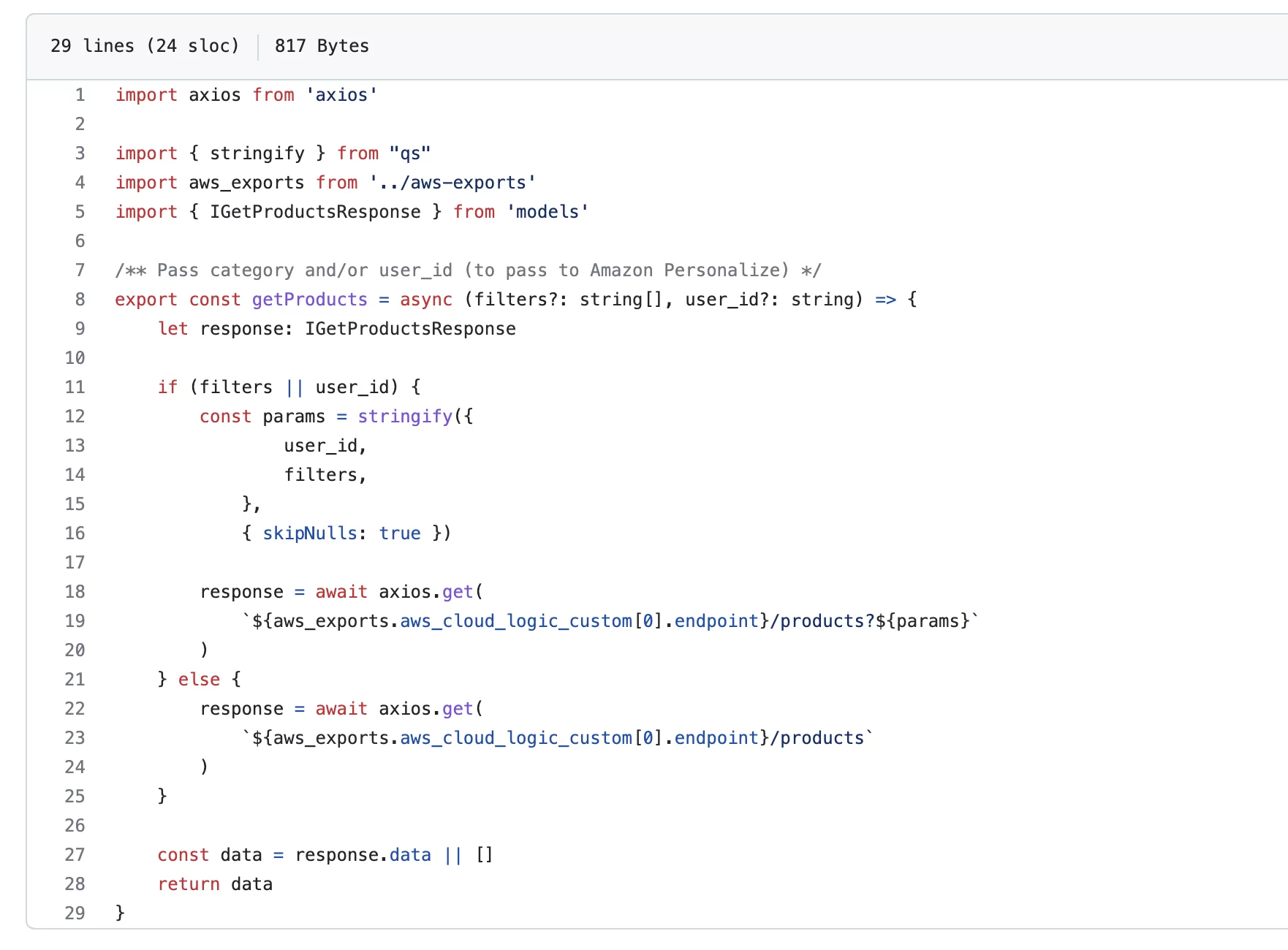
So, if you select a shopper persona from the selection, the user id is passed to the API call, which calls the recommended-for-you recommender. This then returns the recommended items for this user. In this example, this user likes instruments, books and electronics, and on the header it will say “Inspired by your shopping trends” and the recommended items now return the recommended items from our recommender.

If you select another persona, for example, a user that has a liking for footwear, jewellery and furniture, this user will now get recommendations according to their personal inclinations.

Lastly, if no user persona is selected, the API just returns a list returned by the popular-items recommender, and in this case, a slice pepperoni pizza for dinner!
Once both recommenders have been set up, they should then be ready to supply you with your recommendations. However, when new data is available such as when new users, items or interactions need to be added, there are several methods of how they can be added to the system.
For example, we can use the Amazon Personalize Kafka Connector to stream data in real time. However, if there is a large amount of historical records, the recommendation is to import the data in bulk, like what we did and then import the data individually as necessary.
Although available but not included in this demo, you can also stream real time interaction data using events, in particular the PutEvents operation, and the recommendations will reflect the data in real time. For example, we might want to update the model whenever a user adds items to the shopping cart, or when they check out their cart for payment.
Let us estimate the setup and ongoing costs involved for the two recommenders we just added to our e-commerce application. Most of the costs involved are based on the amount of the time the recommender is running regardless of them serving recommendations or not.
Here is a rough and conservative estimate using AWS Cost calculator for Personalize for each recommender, assuming a data ingestion of 1GB a month, 6,000 users, running 720 hours (24 hours, 7 days a week), and not going over the included free recommendations. One recommender per month costs USD 270.05, and USD 540.10 monthly for both.
Using the general understanding that using recommender systems lead to somewhere between 10% to 25% increased revenue, if your revenue is $200,000 per month pre-recommendations, you can expect from $20,000 to $50,000 sales monthly uplift if you opted to use recommendations similar to what we did in this article.
For a recommender system that runs by itself, ingests data on the fly, re-trains automatically, where you don’t need to employ your own data science and machine learning team, and finally contributes more to your bottom line, AWS presents really great value here and is worth your consideration.

Please see the current pricing chart for more details.
We’ve come to the end of our whirlwind introduction to recommender systems, where we’ve explored the high-level AI service in Amazon Personalize. However, we’ve only scratched the surface as this powerful service offers many more features.
For companies with limited resources, or organisations who want to extract value quickly, or when you want something out of the box, Amazon Personalize can be a viable option. With Personalize, we can easily bring machine learning-based personalization to existing e-commerce applications. By ingesting our own user, item, and interaction data, and building recommenders that seamlessly integrate into our codebase, we can create a fully managed recommender system that delights our customers and boosts our bottom line.
However, it’s important to note that while Amazon Personalize is a powerful AI service, it’s still a black box algorithm. It may not cover all specialised use cases, and building a custom recommender system from scratch might be necessary in these cases. Nevertheless, for many e-commerce businesses, high level AI services like Amazon Personalize offer the quickest way to derive value by using machine learning to solve real business problems.
Note: This article was originally published on Cevo Australia’s website
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.