How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


Github link to the full Capstone Project

After recently finishing the Capstone Project, one of the “What’s Next” actions that I have identified was to:
After looking into this a little bit more, I realized that there is a term for this activity - MLOps - the crossover of Machine Learning and DevOps. This relatively new term is defined by Towards Data Science as:
It is an engineering discipline that aims to unify ML systems development(dev) and ML systems deployment(ops) to standardize and streamline the continuous delivery of high-performing models in production.
And there is more to MLOps than just that, in fact listed below are the other operations that are collectively grouped under the MLOps umbrella:
As you can see, model building is merely a tiny part in that process. To facilitate all these activities, there are many MLOps tools available to us, however, there is a one tool popular to most developers which is curiously missing in that list - GitHub Actions!
There’s not much ML resources using GitHub actions as an ML Workflow tool, but having used actions in previous projects, I know that with little work, it can be used satisfactorily, instead of more popular tools such as Azure Machine Learning or Apache Airflow.
In the GitHub workflow above, these are process we went through that ended up with our model deployed to an API in Production:
The model and ML workflow presented here are available in this GitHub repo, free to reuse. Currently this is run manually, but can be easily run using a cron schedule, or as part of your CI workflow, through a Pull Request, or a repo update.
You’ll also notice that this workflow will be running on ubuntu-latest. This is what’s great with using GitHub actions, is that get a selection of GitHub-hosted runners. And they are all free*. All we need to do is select our preferred runner, and install all the dependencies that the workflow needs.
First is to install our preferred Python version and it’s dependencies defined in requirements.txt
Chrome is also required since part of our Feature Engineering is web scraping Wikipedia for some of the weather information. At some stage, we need Selenium to click on links, and further scrape those pages.
Our data comes from Ergast Motor Racing, so we read this API and dump the data into MongoDB. You’ll notice that even though there are secrets involved, we are not sharing these in the actions yml file.
This is an intermediate step that classifies weather information into 6 weather types - getting it ready for the model building process.
The data we got from Ergast is not ready as is, so we we had to engineer a few features. This is easy to do from our workflow by calling some custom-made Python functions.
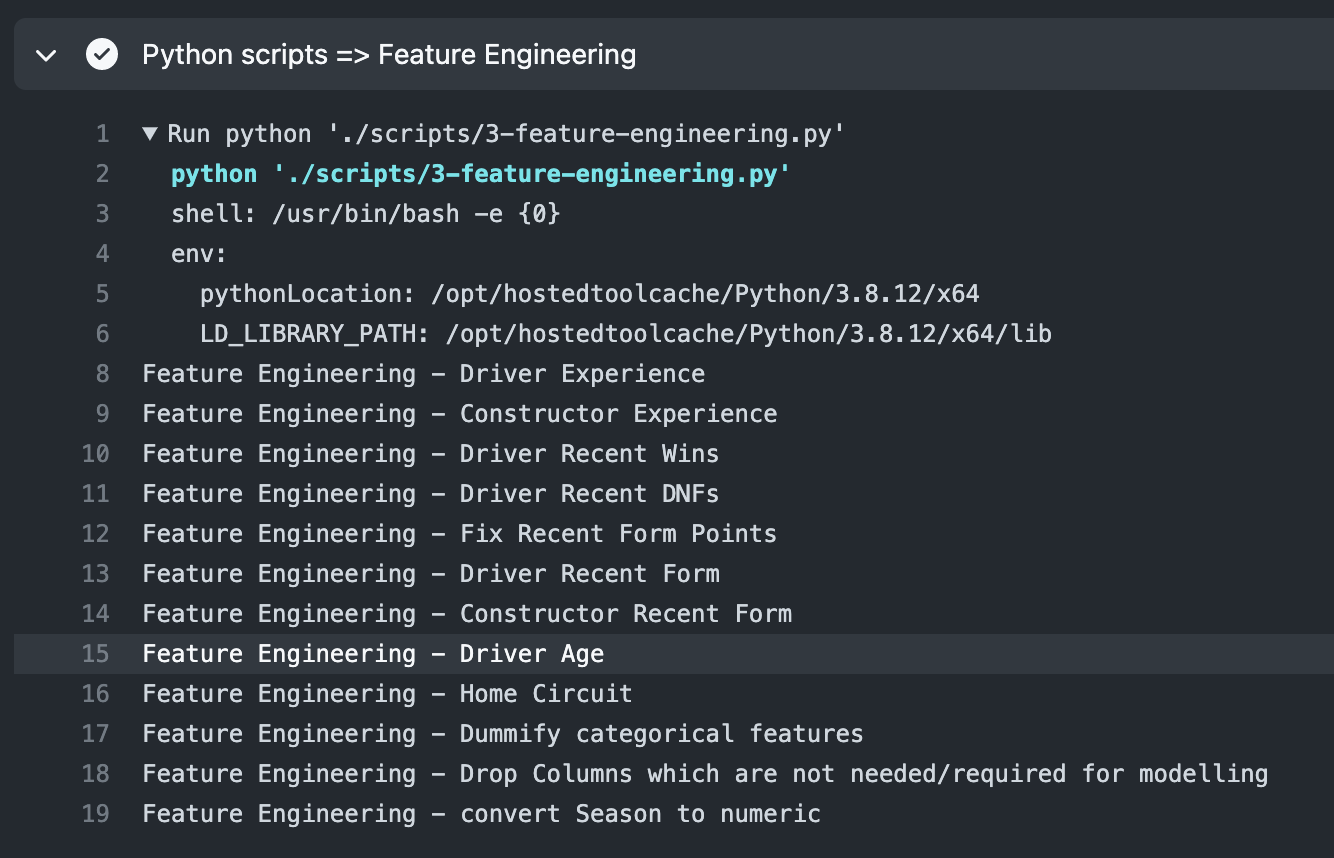
In the previous article we have identified the most optimal ML model for this problem - Bagging Regressor (using Decision Trees), so in this step, we just build the model and generate the Pickle file which our API will use to perform the on-demand predictions.
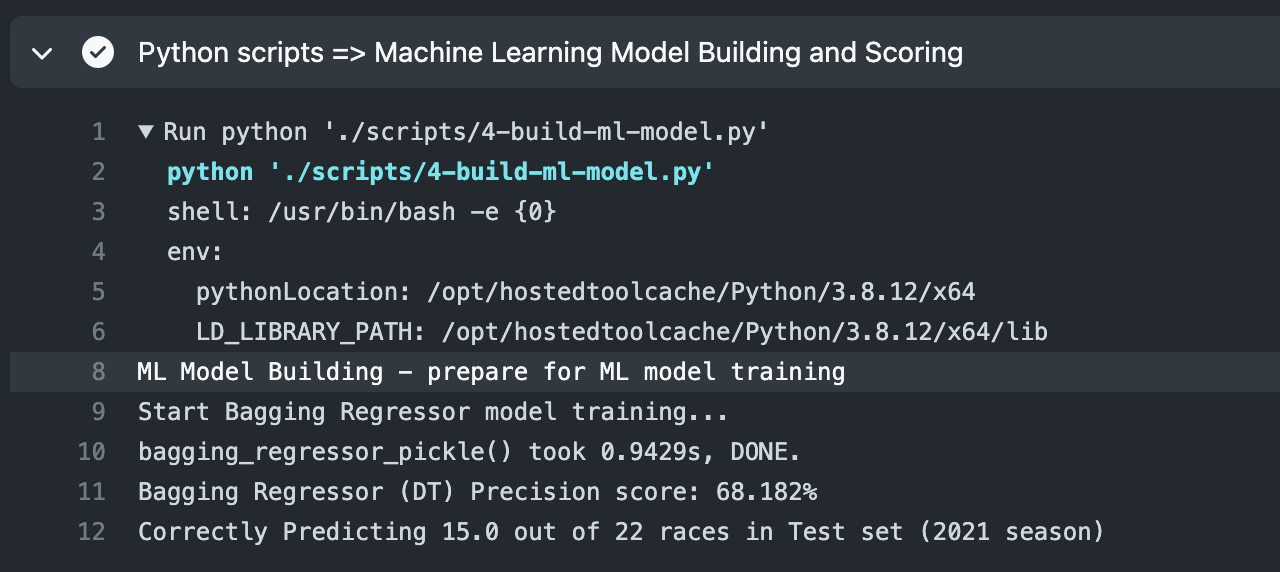
Serverless makes it easy to setup our AWS Lambda as a public API. I wanted to use Pulumi, perhaps let’s do this in another blog post. In the meantime, Serverless was the easiest and fastest way (for me) to push this to our production environment.
The last but not the least! Certainly the most exciting part! The final part of the GitHub MLOps workflow is to be able to deploy our model (and the Serverless API) to production.
I have opted to use Flask, since I already had scripts in Python, so it was minimal work to adapt for the public API.
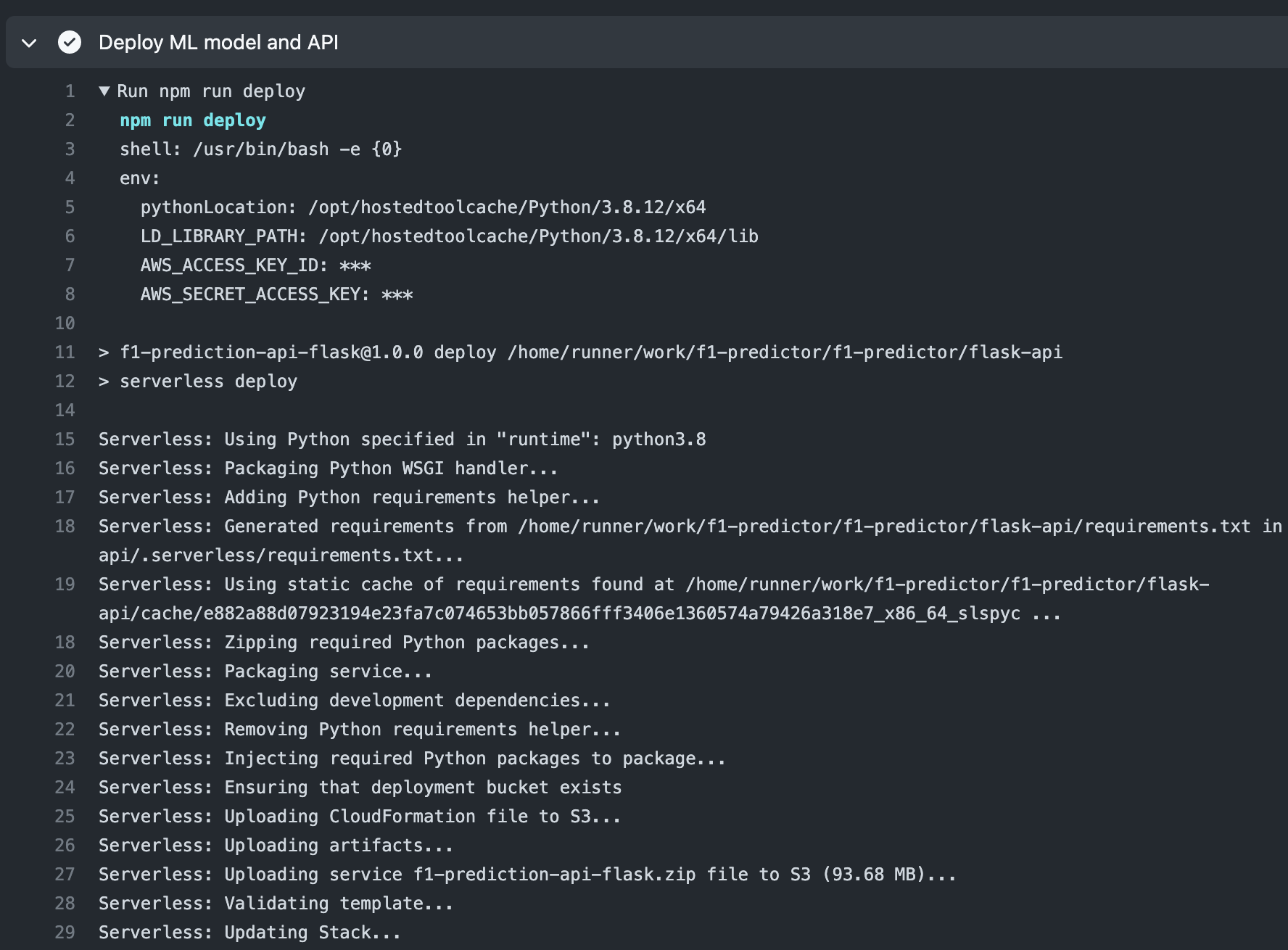
Once deployed, the API is now available to the public. If time permits, I might create a web application that consumes this API, but because this is a public API, this is now ready for prime time!
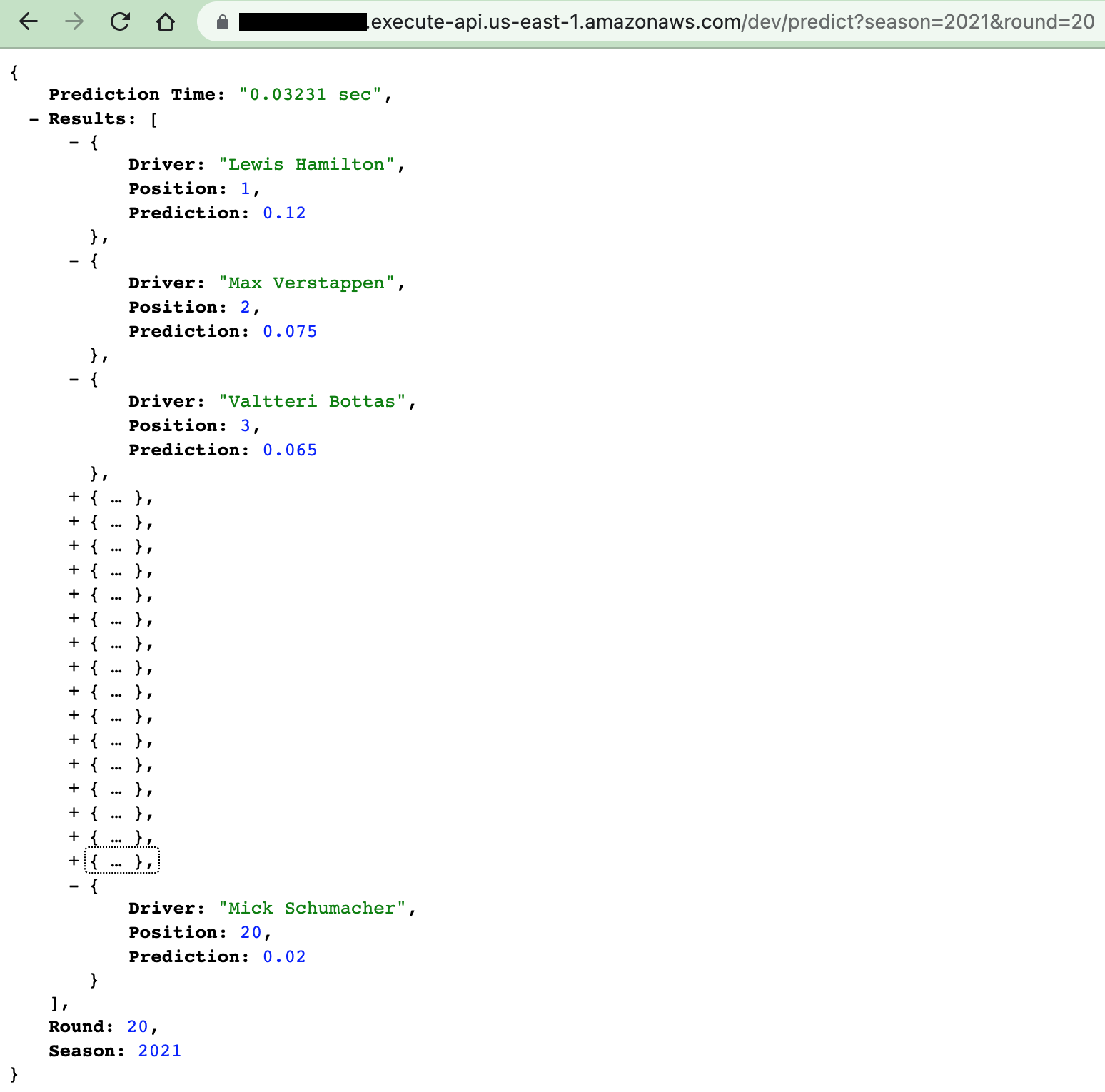
In this article, we have demonstrated the use of GitHub Actions, a general purpose GitHub-based CI/CD tool that many developers love. Although not a tool typically used for ML workflows, its general purpose nature, with little effort, it can be used in simple ML pipelines.
There are some limitations (eg. you don’t want to use it with long-running ML tasks like exhaustive hyperparameter tuning), but in my opinion, it manages just fine for many ML scenarios.
What’s your ML workflow tool of choice?
What capabilities are missing in GitHub Actions as an ML workflow tool?
Github link to the full Capstone Project
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.