How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


For me, one of the more memorable presentations in the recently concluded AWS Summit 2022 ANZ was the one where Carsales described their strategy in scaling their AI/ML Operations. They did not have a large Data Science team, as they had more and more Data Science projects, they needed an effective strategy for scaling their AI operations.
It’s undeniable that leadership is instrumental in any company and project success, however I was intrigued with one of their ML tool choices that helped them reach their goal. I was so curious about this choice that I just had to learn more about it, so in this article will be talking about a sound strategy of effectively scaling your AI/ML undertaking and a tool that makes this possible - Metaflow.
Metaflow was created in Netflix where they used it internally in demanding real-life data science projects and was open-sourced in 2019. And because of its tight experience with AWS, it plays really well with many AWS services, in fact these are all described in detail here.
As I researched about it and used it in a project, I came to the realization that its secret I think is in its simplicity. But don’t let this simplicity fool you.
In a nutshell, Metaflow allows you to create DAGs (Directed Acyclic Graph), so we are now touching graph theory here, but in the end it is really just a fancy term for a workflow, but one that doesn’t form a closed loop.
These DAGs, combined with Python, Serverless and the Open stack, is a very powerful combination. This results in the democratization of the Machine Learning function, making it easier than ever to kick off that personal ML project, or scale your company’s capability in the ML Space.
The typical machine learning process starts with simple experiments, mostly done on laptops or PCs, and this can easily be done with Metaflow. The realization of being resource constrained will come pretty quickly as soon as more complex algorithms or gigantic volumes of data come into the picture.
However, using the same Metaflow Python scripts (oh yeah you can use R too), plus a sprinkling of decorators, you will have the ability to leverage almost infinite cloud compute (both GPU and CPU), gigabytes of memory, and a long list of mostly open source SAAS/PAAS tools.
Remember the feeling of trying to select a tool, but feel paralyzed of picking one for fear of being stuck with it forever? Metaflow will not only enable you to easily pick and integrate an ML tool to your project, it will also allow you to abandon that choice relatively easily once a better one comes along, and be rest assured that you are using a tool that was battle tested in Netflix.
This article comes with a simple example project and although the algorithms it needs don’t require the resources that a more complicated model requires, it represents real world data, and was originally created when I started following Formula 1 more regularly and was looking for something that I can learn Data Science and ML with, and wouldn’t mind spending countless of hours with.
However, if you want a more realistic problem, more worked-out open source examples are found here, and here, and hopefully you will believe me that you don’t need to be the size of Google to be able to tackle these types of Data Science problems.
The example project I have here is a very simple workflow that although consumes real-world dataset, was really only created for learning purposes. Following image shows some of the technologies I used to get it working.

Most of the code is from my General Assembly capstone project - where I go through the process of consuming data I have pulled from a public API, do a bit of feature engineering, integration with another popular Machine Learning tool called Comet ML and Github Actions, then train multiple algorithms in parallel, all repeatable since Metaflow keeps track of all experiment metadata.
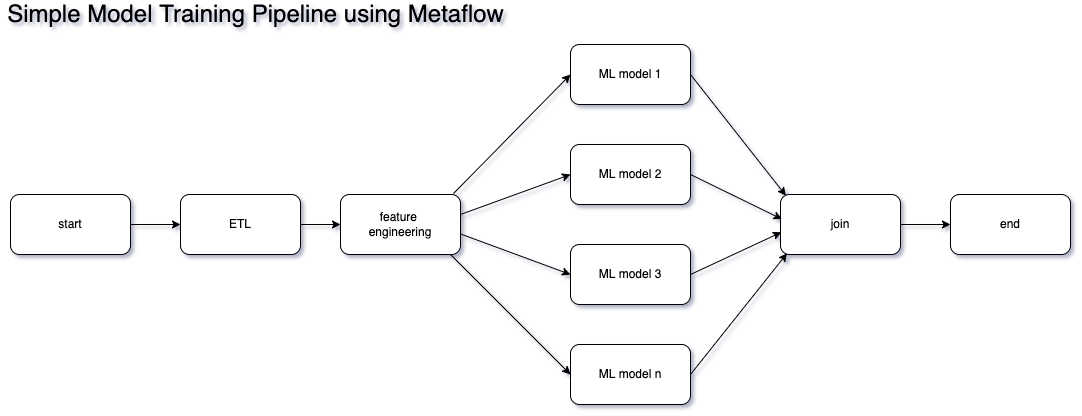
The intention is to show how easy it is to leverage Metaflow not just for orchestrating the parallel workflow, but also for enabling the repeatability of your experiments. It finishes after the parallel training and testing of models, however in reality you could do a myriad of tasks after this, such as model selection, model deployment or even scheduling for retraining.
Code is freely available here.
The main disconnect with many new to Data Science and Machine Learning is the difficulty of shipping models to production. Many Data Science courses may teach you the basics of the whys and hows of using algorithms and model building, however, throw you to the wolves with deployment and scalability. With Metaflow, it is easy to create ML pipelines for development when you’re working on your laptop, and when it is time to push it to production, there will be minimal work involved in moving that workload on the AWS cloud.
The example project shows that it was easy to create a workflow that performs feature engineering, model training and testing in parallel, and easily integrate 3rd party tools. This is only the tip of the iceberg, it really does enable one to have the ability to do ML using the open stack, 3rd party SAAS offerings, many free tools, and do ML at par with the big boys.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.