How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


I recently picked up GraphQL as the next technology to learn in a bit more detail. In my next few posts, we will navigate our way through the GraphQL landscape. For our first post, we will look at the top 7 reasons why GraphQL is better than REST Api, and how our customers will love the apps that we create with it.
When I started learning GraphQL, I began playing with an existing api (Star Wars API), and the first thing I encountered was the GraphiQL tool. This is a built-in tool that GraphQL servers optionally ship with their API. Servers based on Apollo currently use GraphQL Playground, a built-in tool built by Prisma and based on GraphiQL.
This tool allows you to ask the API what its capabilities are and enables you to send requests and get data back from the GraphQL server.
This is very compelling, as I was able to quite simply ask the server for data, I didn’t have to go anywhere to read API documentation as it’s all there, and I didn’t have to use a separate application (like Postman, although you can if you wanted to).
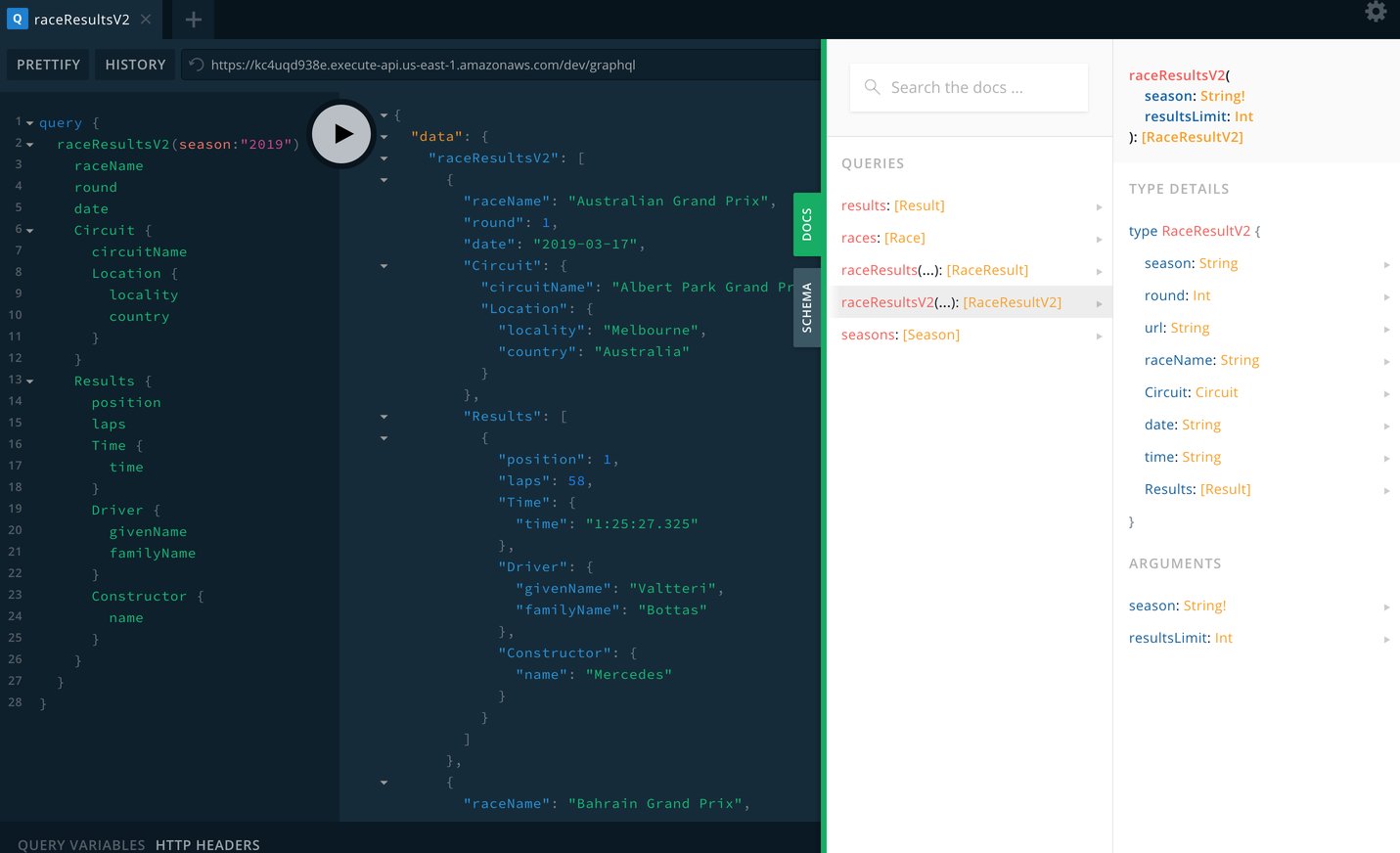
And when I finally moved to the frontend, it was a simple case of copying my GraphQL scripts from GraphiQL, and pasting it in Javascript. All the usual libraries that we used in REST API can be used with GraphQL, eg, fetch, axios, superagent, or simply just XHR, to name a few, so it is really quite easy to get productive on the frontend.
And if you want to leverage more advanced functionality, you can try Apollo and its ecosystem of libraries and tools for both Server and Client use.
Since GraphQL has type safety built into the system, it is simple to identify the validation requirements through the GraphQL playground. On the client, validation hints are supplied by the tool, and if you need some guidance, you can always bring up the API documentation anytime.
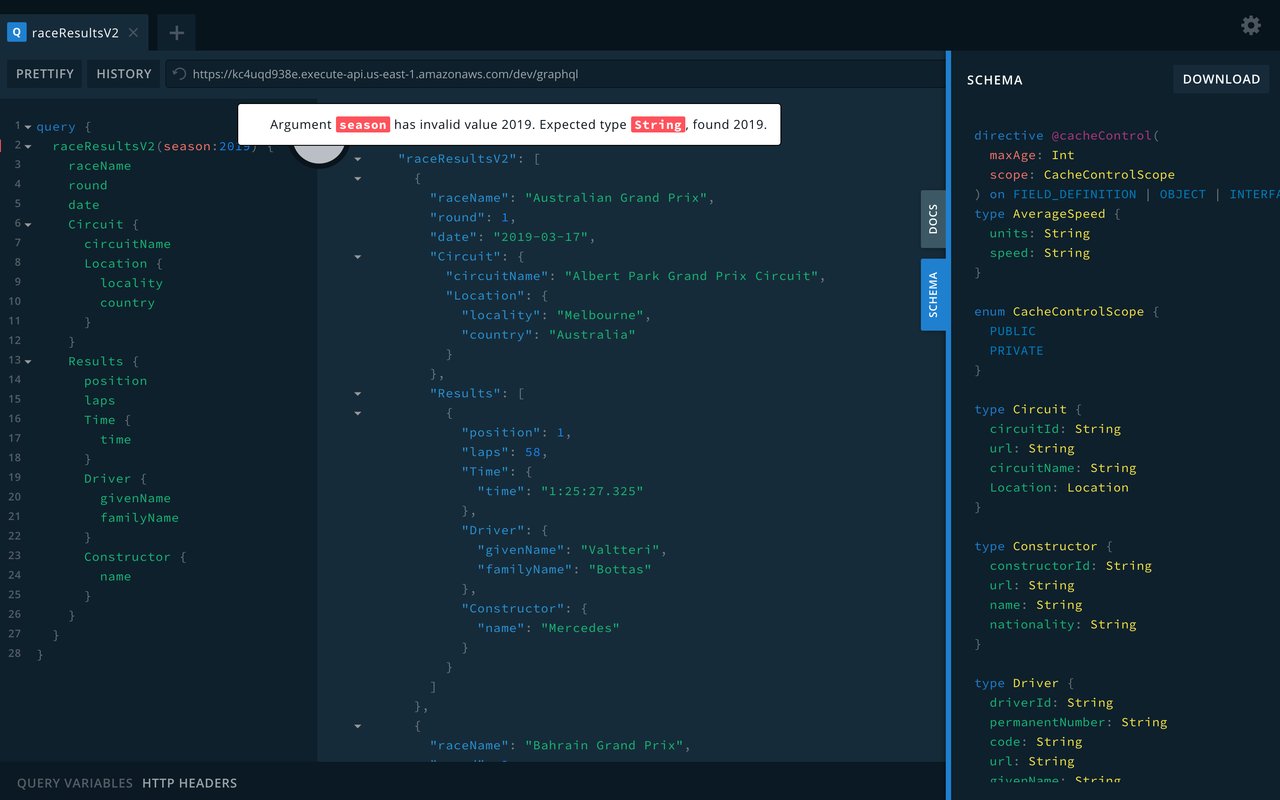
However, if requests end up reaching the server, it can respond with rich validation error details that you can use on the client for user interface updates.
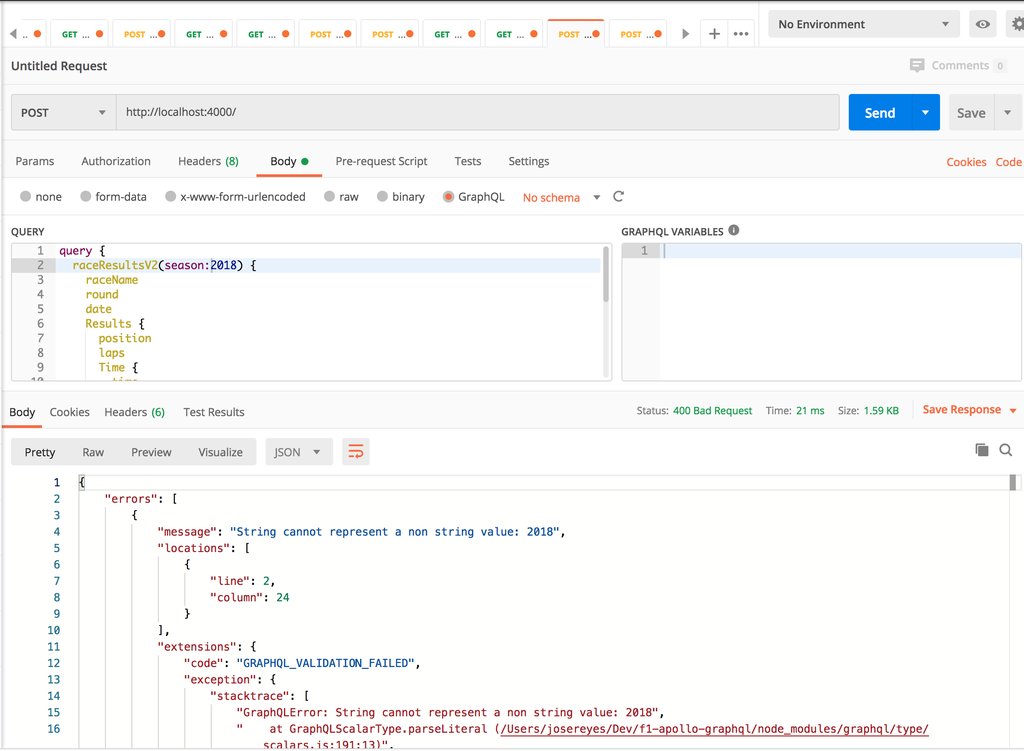
When GraphQL was announced in a Facebook blog post back in 2015, one of the features that was advertized is that it is Version Free. And it is still true till today, however, there is still a need to communicate appropriately between the frontend and backend teams in the case of removing functionality.
The shape of the returned data is determined entirely by the client’s query, so servers become simpler and easy to generalize. When you’re adding new product features, additional fields can be added to the server, leaving existing clients unaffected. When you’re sunsetting older features, the corresponding server fields can be deprecated but continue to function. This gradual, backward-compatible process removes the need for an incrementing version number. Lee Byron, Facebook
Typical web applications follow the usual request-response architecture, however, GraphQL supports subscriptions and libraries like Apollo or Relay have their own implementations, based on WebSockets, with its persistent network connections.
Subscriptions are a GraphQL feature that allows a server to send data to its clients when a specific event happens. Subscriptions are usually implemented with WebSockets. In that setup, the server maintains a steady connection to its subscribed client. This also breaks the “Request-Response-Cycle” that were used for all previous interactions with the API.
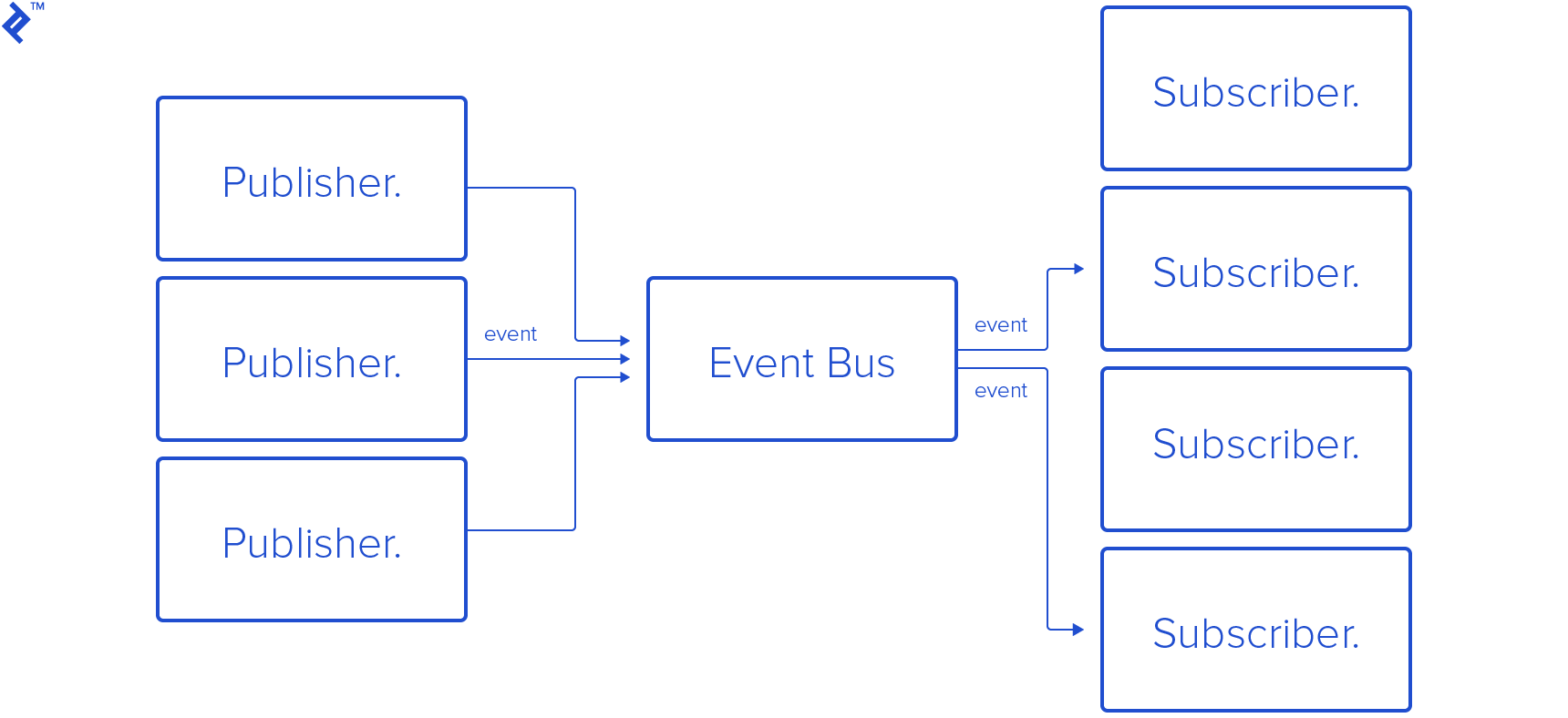
Event based communication like a publisher-subscriber model avoid the need for the clients to poll the server for new information. It allows for simpler code on the client, however, server code can be a bit more complex. Lucky for us, libraries from projects like Apollo and Relay, remove the need for us to create it from scratch.
I have already alluded to the self-documenting features of GraphQL when I talked about GraphQL Playground above. Each deployment has the capability to include it as part of the build, however, if you have elected not include this with your server, then schema information can be asked from the server through GraphQL introspection.
A GraphQL server is typically served from a single endpoint, contrast to REST Api where multiple endpoints are utilized to represent separate resources. You simply advertize one endpoint to your clients, and with the built-in Api documentation, client development is a breeze. This single endpoint will deliver the full capabilities of the server including queries, mutations and subscriptions.
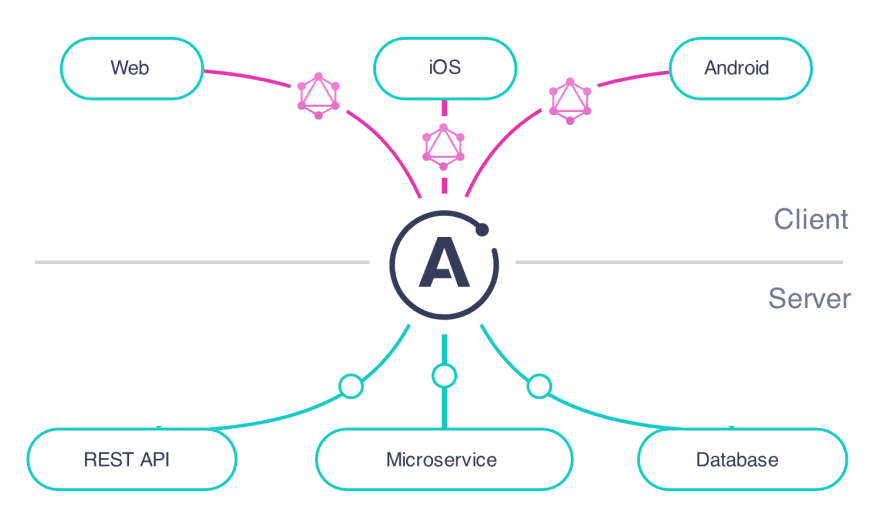
And when you use GraphQL as a aggregator to multiple services/data sources, which can span database calls, wrapper to REST Api services to other GraphQL servers themselves, this single exposed endpoint can be your gateway to potentially vast functionality to your clients.
And finally the top reason on why GraphQL is better than REST, is that a client is able to request only the data that it needs, no more, no less. Compare this to REST Api, where you are limited by what the server had been programmed to return.With REST, you will either end up with more data than you actually need (over fetching), ending up having to massage and filter out the required data on the client.
In REST scenarios, it is also common to see cases of under-fetching, where you end up having to send multiple requests to the server to get all the data you need on your client pages.
When over-fetching, the optimizations afforded by GraphQL can translate to substantial savings in bandwidth on the clients, specially when these are on mobile devices as in the case of mobile browsers, or on mobile apps. When under-fetching, the time savings of multiple separate requests can be a substantial savings too, if not for the amount of data downloaded, but the latency of having to wait for all the multiple responses to arrive.
So there you have it, the top 7 reasons why GraphQL is better than REST. Although it looks as though I am saying there is no place for REST anymore, this further from the truth.
GraphQL is by no means a silver bullet. Because the GraphQL specification is still being worked on, for example, there is no detail for things like Authentication, or File uploads for example, where you will have to add your own implementation, they may not be the best technology to use in every case.
If we scan through the 7 top reasons above, you will find that there is a theme, all of them are mindful of our users (either the end-user of the client applications, or the client developers themselves), and give us a clear advantage over REST.
GraphQL allows us to transform our applications into better and more efficient applications that our customers will love, and our developers love to create.
These picks are things that have had a positive impact to me in recent weeks:
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.