How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


In the past I’ve inherited, developed and maintained a microservice-based project and I would like to share some of the things I have learned with you.
The web frontend of this web application used ASP.NET MVC and ReactJS, the backend a mix of .NET Web APIs and Lambda APIs (we used AWS), about a dozen of them. It also used a few other 3rd party downstream services. There is also a mobile clients for both iOS and Android stores.
This project was developed by a small team, about from 2 to 4 fullstack developers working on it at a time. There were two client apps - a web application, which was actually a couple of web applications brought together by a proxy server front end. And a mobile application for both major platforms.
In a typical client application, like in a mobile app or a typical SPA, one directly calls the microservice endpoints. However as the application evolves, more information and functionality gets squeezed into each page, and it is not unusual to have to do multiple calls to different microservices and compose the page from the data from all these.
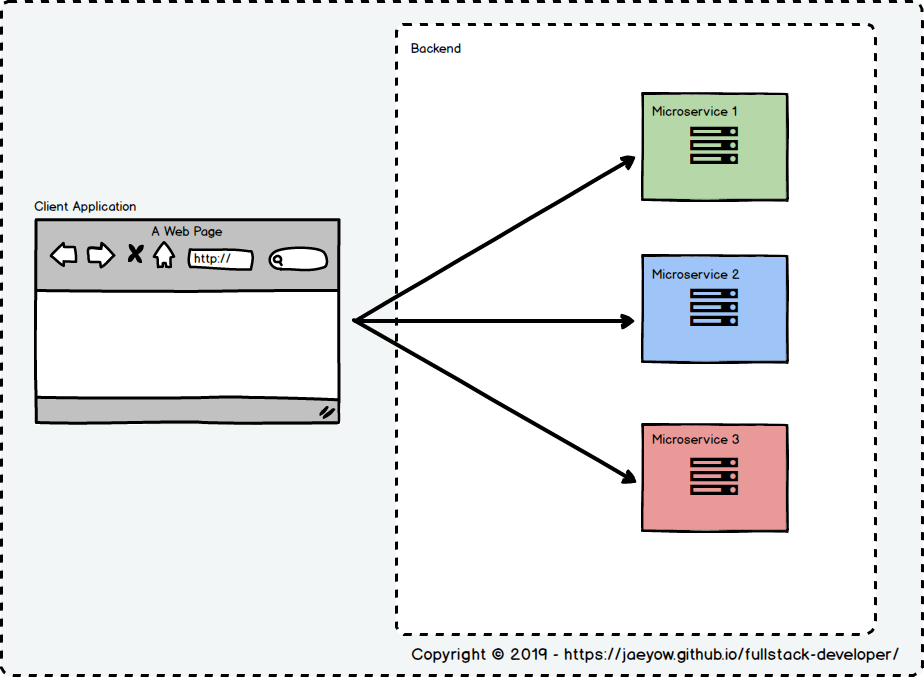
However, in this hybrid ASP.NET MVC/ReactJS app, the pattern used to compose the page is a bit different, so lets examine the situation.
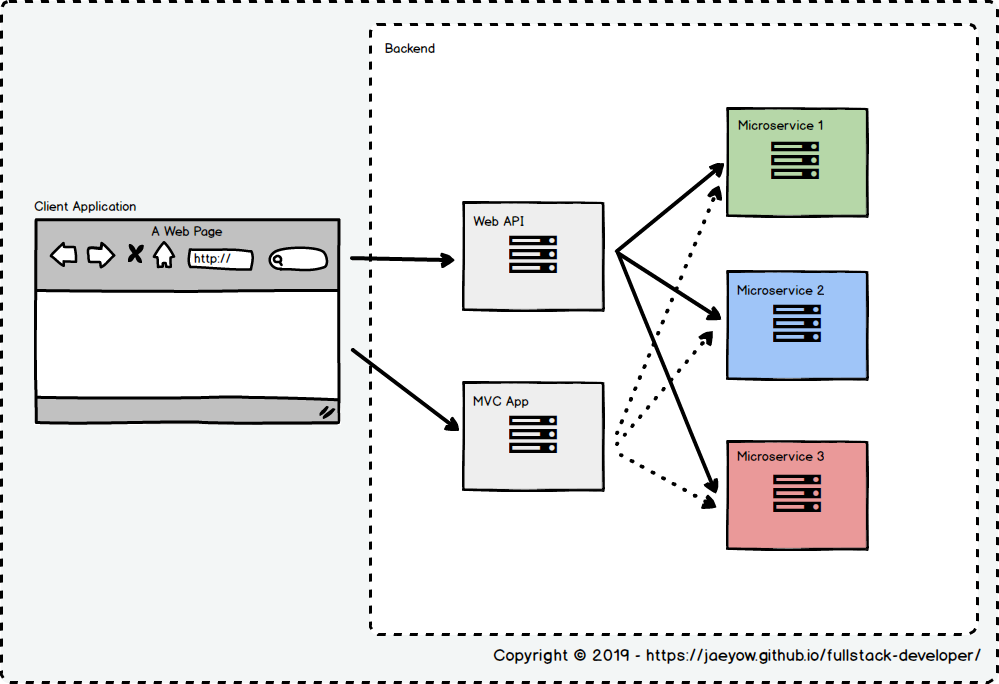
In the course of initially loading a page the MVC App creates the Html skeleton including the bootstrap data that the page needs to achieve first paint as soon as possible. It also loads all the javascript, styling and images to make this possible. Now once the page is up in the client’s browser, React takes over and takes care its interactivity helped by the presence of a separate Web API in turn talking to all the services.
At first I was not quite clear why this separate Web API was required. Then after some research, I have stumbled upon the BFF Pattern as masterfully explained by Sam Newman in the post. Actually it was Phil Calcado who was one of the first (if not the first) who came up with this pattern.
The mobile application also followed a similar architecture - both the iOS and Android apps talked to the downstream services through a dedicated Web API in the middle.
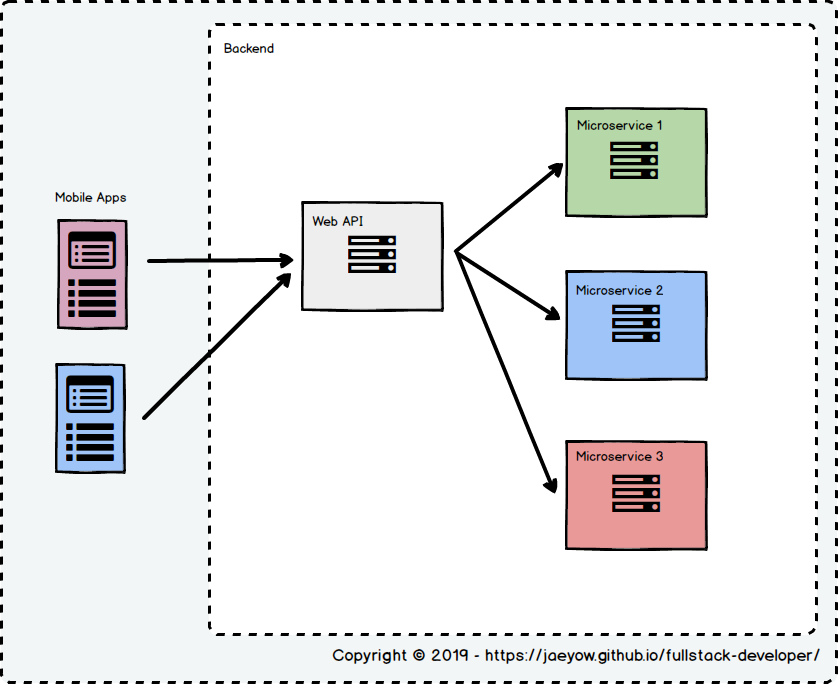
But they all point to the same BFF Pattern. Without having to repeat the articles in the previous section, let me say that BFF pattern is to simply have a backend API for each client, in which the development is owned by the client development team (shown in the blue shaded box in Figure 3).
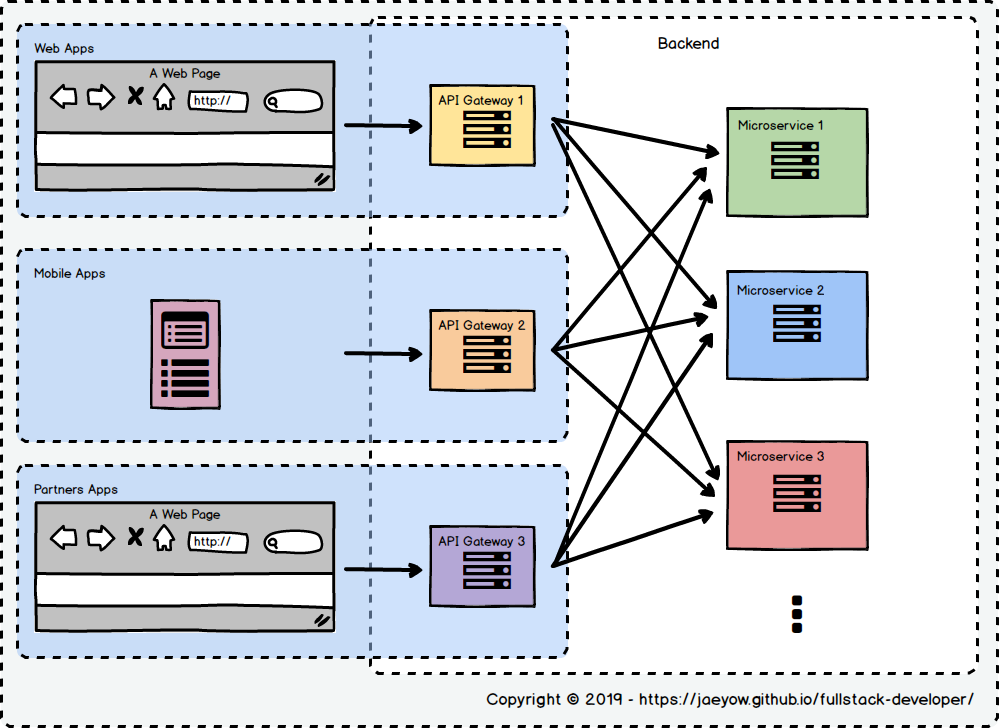
Using the BFF Pattern is more than just a data pass-through from data provider to the clients. These are the advantages for using this pattern:
it can serve as a gateway routing/proxy server: where the client talks to one API gateway, which routes the calls to multiple downstream services. This insulates the clients from changes when downstream services URL changes.
it can function as a request aggregator: reducing the chattiness of the client application. The client can send just one request to the API Gateway, which can send multiple requests to one or more downstream services. It can also gather all the responses and send them back to the client application. This can lead to performance improvements as running multiple requests from remote browser or mobile apps are more expensive than running them from each API Gateway.
it can contain code that handles cross-cutting concerns: such as authentication and authorization, logging, caching, retry policies, load balancing, etc. This can help in making the downstream services’ code much more simpler by not having to handle these concerns there.
it can promote consistent error handling: many service providers return errors a bit differently, so we can handle and translate error fault codes from different downstream services in a consistent manner so that the client application can be simpler.
enables development team’s autonomy and agility: BFFs enables and empowers development teams to be more in control of their projects. Instead of waiting for the “backend” team to deliver the updated API, and be at the mercy of their delay, control goes back to the client application team to be more on top of their delivery schedule.
enables better maintainability: because there is an inherent separation of concerns that this pattern promotes, this leads to better maintainability as parts of the system are insulated from certain changes.
more moving parts: more moving parts means there is more things that we need to develop, build, deploy, and monitor. Put it simply there are more things that can go wrong.
moving the coupling around: whereas previously there was client application to downstream services coupling, the coupling has now moved to between the BFF and the downstream services. In the case of a mobile app client, or any client for that matter, maybe that is a compromise you are willing to take.
can introduce latency: in some instances, it may lead to more latency, however, a more chatty client most probably will have a longer response time.
more development by the client app team: because the BFF will typically be developed by the frontend team, this will mean more development and more time will be needed to develop the vertical solution
more possibility of code duplication: because following the BFF pattern, we tend to create an API for each user experience, the tendency is to duplicate code from one BFF to another, specially in the cases of similar or same functionality. However, in my opinion this is a compromise I am willing to take, in the interests of agility and autonomy.
GraphQL: The BFF pattern started because of the generic service providers that cannot give what the client actually needs. This is the problem that GraphQL can solve. This enables a service provider to only return what a client needs. There is no concept of a generic API anymore, now we have an API that gives us exactly what we need. As awesome as this may sound, this may need more thought as it can mean either rewriting the downstream services to use GraphQL, or actually writing your BFF in GraphQL. You will have to assess this in your project as to what is possible.
Web Components or some other frontend UI composition technique/technology: maybe there are better technologies in the frontend space that although we still have to deal with multiple requests aggregation, would allow us to structure and manage our frontends similar to how we do our microservice backend. This compromise might help us manage our solution much better. More on micro frontend approach in a future post perhaps.
Don’t change: yes this is another option, but we will just have to be careful and manage the changes effectively. But, where’s the fun in that?
The arrival of microservices has contributed to software development challenges. Where previously apps talk to a general purpose API backend or service provider directly, this has proven to be problematic when changes need to be introduced both in the frontend, or at the backend.
I have listed down a few advantages in adopting this pattern. However among those, for me, I think promoting better maintainability and autonomy and agility are the most compelling reasons to use it.
We get better maintainability because we have narrowed the scope of the API, where you are not anymore trying to make everyone happy but just your own application client.
We get better autonomy and agility, because we have taken back control of the development of the backend service. And no longer are you at the mercy of the downstream service provider developers as both the frontend and the BFF are now developed by the same team.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.