How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


A while back I was finishing work with an employer and was due to join my new team. I remember feeling excited when I heard that the new project will be using monorepos. I did not have a clue what monorepos were, only I’ve heard that that’s what the big boys were using.
Definitely not mainstream (still not these days) they were supposed to promote better collaboration, and give the teams using it full autonomy and are perfect for when you’re anticipating the project to scale.
Yeah, OK that sounds good, however, I just didn’t understand how just by co-locating all your sub-projects into a single repository will magically give you all the advantages mentioned.
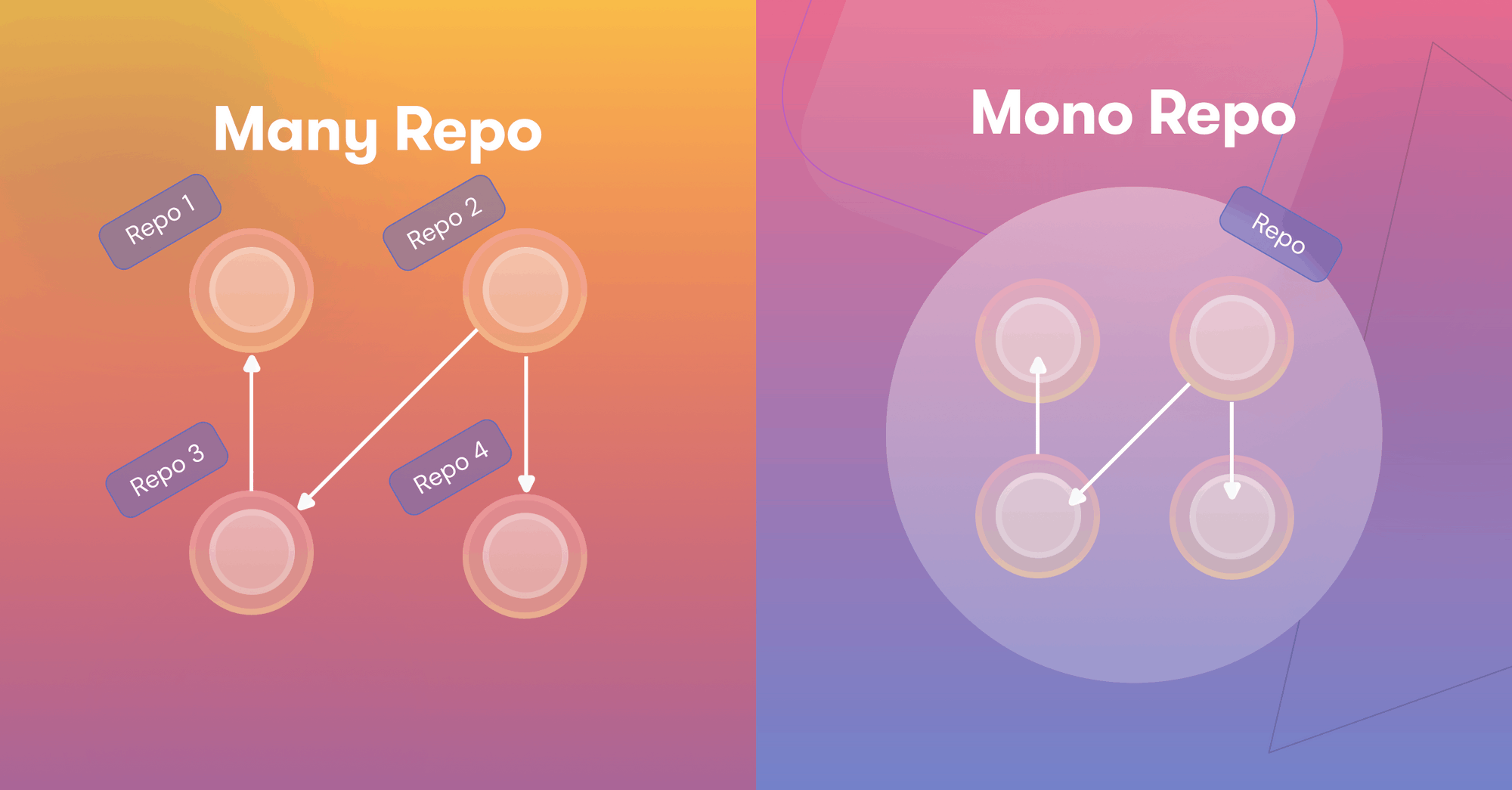
Yes, Monorepo is code co-location, but there is more to it than that.
Just putting several projects in one repo does not make it a monorepo. In fact, if that’s the only thing that we do, we are creating a monolith. A good monorepo enables you to create distinct and separate projects, that have well defined relationships and dependencies.
This is a very common misconception in software engineering, where as far as I can remember, we have been conditioned to put everything in its own repository to encourage team autonomy. But it also promotes isolation that creates silos within the team and that essentially kills collaboration.
Monorepos excel with dependency management now that all the code is co-located in one spot. Because a monorepo can contain many disparate projects that may have deep and non-trivial relationships, monorepo tooling are optimized for build speed.
It can cache previously performed operations, so that running them again will skip the work that has already been done to produce substantial time savings.
The node_modules folder needs no introduction, its that deep dark place where all project dependencies end up in. Current monorepo tooling can save a substantial amount of disk space by hoisting common dependencies to the top level, so that all lower level dependencies are satisfied from there instead.
With monorepos, version configuration is simple, there is only one version, and this essentially is a snapshot of the system removing the need to manage the multiple different versions of your application and its dependencies.
Imagine all your system in one repo. Web frontend, IOS and Android mobile app, shared libraries, APIs, Lambdas, IaC, scripts, etc. The ability to be able to work on a task and do everything in the same commit, that is possible with monorepos.
Many of the monorepo benefits are not possible without the advancements in current monorepo tools.
Tools like Lerna, Bazel, Nx, Rush, Turborepo, to name a few. Lerna is probably the grand daddy of all monorepo tools. CRA, Babel, Jest are a few projects that use it. Bazel has been refined and tested for years at Google to build heavy-duty, mission-critical infrastructure, services, and applications. Turborepo is the monorepo for Vercel, the leading platform for frontend frameworks. These tools can help keep your monorepo workspaces fast, understandable and manageable.
Monorepo.tools is an excellent resource detailing the many intelligent features of these tools that help manage your monorepo projects.
Because all the team’s code (maybe even the whole organization’s) exist in the same repository, monorepos encourage code sharing, transparency and cross team collaboration. This does not come for free, though. There will be more noise, but with good management and the help of efficient tooling, this is all possible.
Software engineering is as much technical as it is people. Yes monorepo is a technical strategy to structure your project and workspace.
However, it is actually much more than that. Because is encourages people to collaborate effectively and work efficiently together, it represents a change that probably many software teams need today.
Moving to monorepos represents a paradigm shift in software engineering. There are reason’s why many organizations have made the shift. There are obviously many gains with using monorepos that made these organizations move. But because it represents a fundamental change and shift in thinking, there are also many detractors.
Because on the surface what may look like a simple change in project and workspace structure, is actually an organizational change, and that can be hard in any industry.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.