How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


Fully working source code is freely available here.
Github Actions, Metaflow and AWS SageMaker are awesome technologies by themselves however they are seldom used together in the same sentence, even less so in the same Machine Learning project.

Github Actions is every software developer’s favorite CI/CD tool, from the makers of Github. It is used by millions of developers around the globe, and is very popular among the Open Source community and is mostly free.
Metaflow, the Data Science framework developed in Netflix, is a very attractive proposition as it allows one to easily move from prototype stage to production, without the need for a separate specialist team of platform engineers, enabling your data science team to be more productive.
And lastly, AWS SageMaker has been in the ML game for a while, and AWS is still the leading Cloud provider (for Cloud services and ML workloads) in the world.
It all boils down to the use of Metaflow and its inherent scalability. You can start using Metaflow even when you are still running your experiments on your laptop.
But when you want to move to the cloud, you will need a basic (and free/cheap) scheduler/orchestrator to kick-off your workflows - enter Github Actions. There are some limitations with using Github Actions as your workflow scheduler/orchestrator, but for simple projects, or in the case when you’re leaning on SageMaker for your training and deployment workloads, it is more than sufficient.
And as to AWS SageMaker, teams that are already on the AWS ecosystem will appreciate the almost unlimited deployment possibilities in their fingertips. Typically SageMaker workflows are created and controlled through the AWS console, but to enable us to go to Production in this article, we will be using the AWS Python SDK, through Metaflow.
A typical Data Science project starts with the Prototyping stage, and the tool which is the perennial favorite among data professionals is Jupyter Notebooks. And this is also my personal playground when I start looking at DS and ML problems, and it’s awesome for quick iterations.
It allows me to quickly play with the data, create visualizations, transform data, train and deploy them to an extent. It is awesome, and it has become my favorite too. However, when and if the project needs to progress to production, we need a better tool and work practice. Many teams still deploy to production with their laptop and Jupyter Notebook setup, and though you can, you really shouldn’t.
The main characteristic of production workflows is that they should run without a human operator: they should start, execute, and output results automatically. Note that automation doesn’t imply that they work in isolation. They can start as a result of some external event, such as new data becoming available. –Ville Tuulos, Effective Data Science Infrastructure
Because my background is in Software Engineering, I’ve been honed to the process of continuous integration and deployment for virtually all my software projects. That all projects should have the ability to be built and deployed at a click of a button, or as a result of a schedule or event, even multiple times a day if required.
Everything automated, everything typically stress-free unremarkable events.
This is exactly what we want to happen when we want to push ML projects to Production. We want it to be automated, and we want it to be a stress-free unremarkable process.
As I’m currently studying towards the AWS ML Specialty certification, I wanted to play a bit more with the built-in algorithms that SageMaker has in its portfolio. One of the first algorithms I checked out was Linear Learner. It’s a type of supervised learning algorithm for solving classification and regression problems.
I did not create the notebook from scratch by myself, however I based it from the examples in AWS SageMaker - An Introduction to Linear Learner with MNIST.
I basically ported it into Metaflow DAGs as seen in the flow image below:
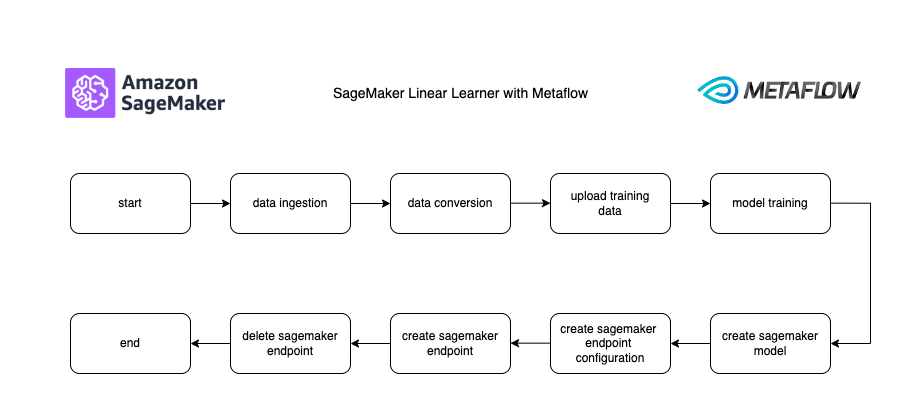
I’ve leaned on Python for all my ML work, and Metaflow is based on Python (you can use R too), and AWS SageMaker has an extensive SageMaker Python SDK at your disposal.
Looking at the above flow, we are able to do an end to end ML workflow including model training on AWS SageMaker, leveraging on AWS ML instances for ML training workloads, to endpoint creation with your required AWS instance type.
For brevity, I have skipped the part of serving that endpoint to the public, but this can easily be done by serving the endpoint behind an API Gateway and a Lambda. Perhaps we can do this operation in a separate article. Also take note that we have deleted the endpoint, before we end the flow to avoid the dreaded AWS bill specially now as we are just checking out the service.
In this sample project, I have also leveraged on Github Actions as our workflow scheduler/orchestrator, this is really to prove that Github Actions, even in the free tier can really be used in ‘production’, albeit in a very simple flow.
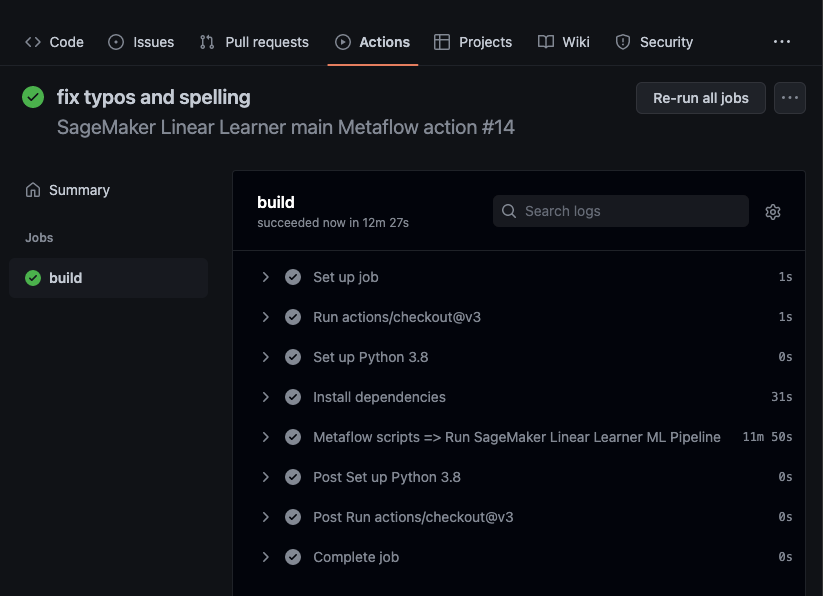
Although it’s worth mentioning that AWS Step Functions is being pushed by Metaflow as the workflow orchestrator of choice if we really want one that that is robust and easy to use. Metaflow has an official Step Functions integration available. Yes this is also a topic that I’d like to cover in a future post.
Metaflow performs the SageMaker operations - from model training, to model creation, to creating and testing the endpoint, all through the Python SDK, where we really have the power of SageMaker in our fingertips.
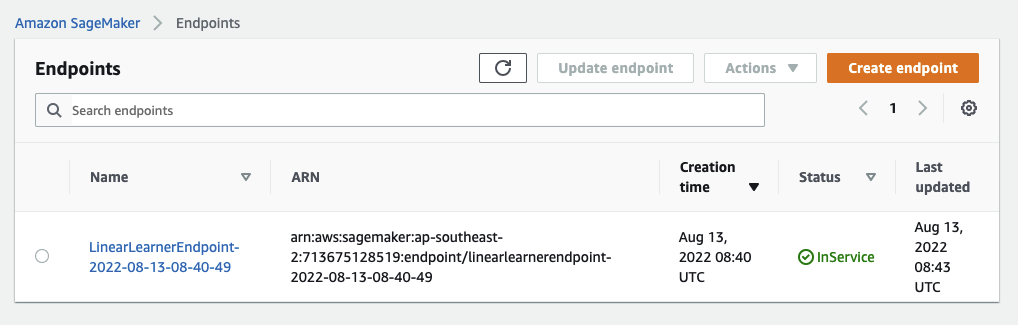
In this article we’ve ported the Python code from the MNIST AWS example, trained our ML model in AWS SageMaker, built, and deployed the model in a SageMaker endpoint in production. This is all automated by Github Actions (in this example the workflow gets triggered by a repository push), and brought all together and made possible by the awesome Metaflow.
Thanks, I’ve made the source code freely available here.
Let me know if you have any concerns, or any questions, or if you want to collaborate!
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.