How to Build, Train and Deploy Your Own Recommender System – Part 2
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.


We now continue our GraphQL journey as we try out Apollo to implement our first GraphQL server. We’ll use Apollo server - an open-source spec-compliant GraphQL server which is production-ready and is compatible with all GraphQL clients.
As with all posts here in Fullstack Developer Tips, all source code is available open-source in Github, and for this post, we use Github Actions for the first time to push it to production. I wanted to deploy this to the cloud, and my choice of cloud provider is AWS. To leverage free hosting, we will be deploying the GraphQL server to a Lambda using Serverless.

I love Formula 1, and for this GraphQL server, we will be exposing the Formula 1 results and standings since 1950 when the first race started. I don’t have a database though, instead, we are sourcing our data from Ergast Developer API, and surfacing it with our GraphQL server.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// copy the following GraphQL query and use it with the server below
query {
raceResults(season: "2019", resultsLimit: 3) {
raceName
round
date
Circuit {
circuitName
}
Results {
position
number
points
Driver {
givenName
familyName
}
}
}
}
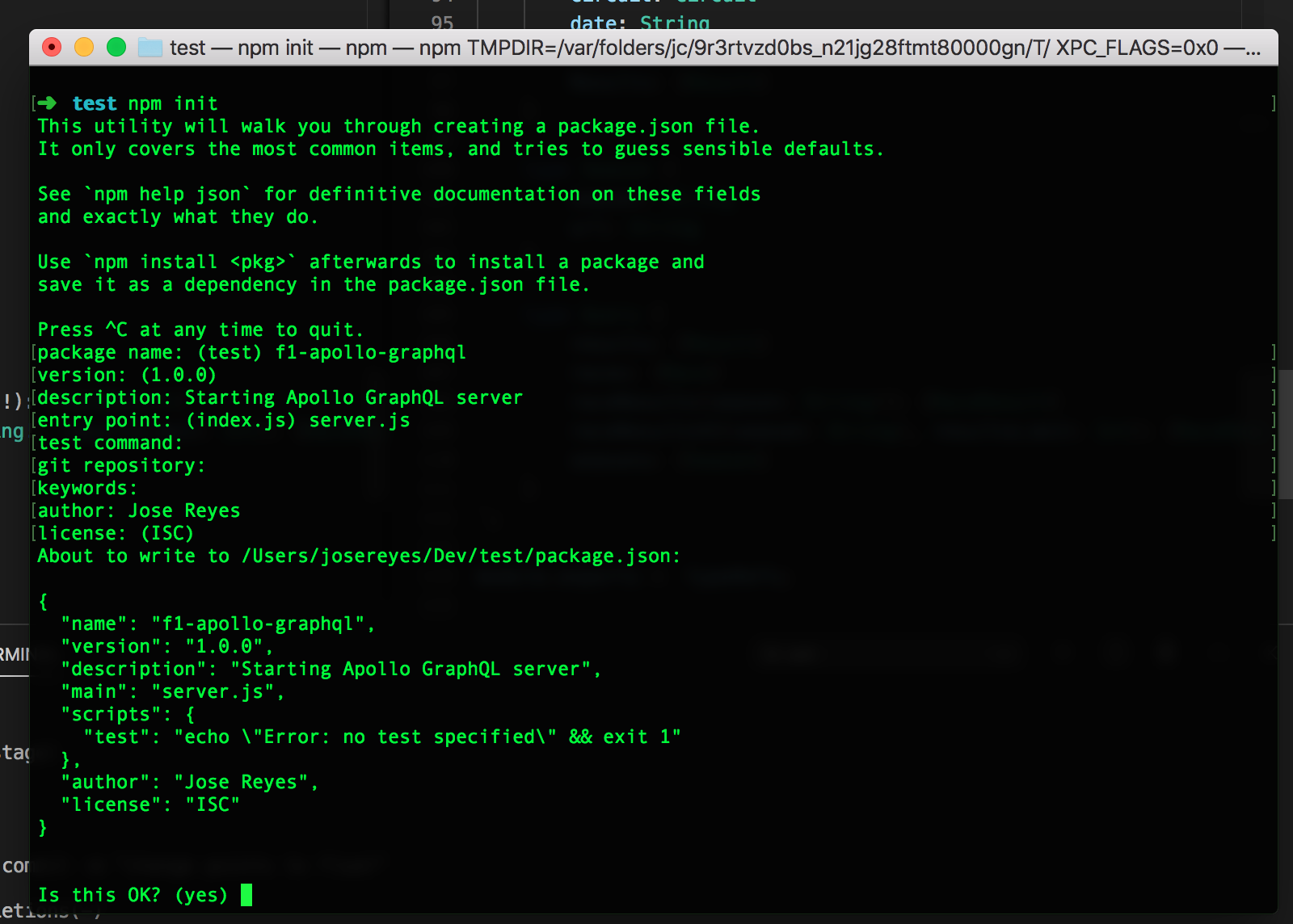
Because we are implementing this GraphQL Server using Apollo Server, a NodeJS based implementation, we are going to start the project using npm init. The following image shows this process, where when finished will generate an empty project with a package.json file. We’re well on our way.
1
npm i apollo-server graphql apollo-server-lambda nodemon axios promise dataloader
Following explains why we need the dependencies above:
apollo-server - is the core library for Apollo Server itself, which helps you define the shape of your data and how to fetch it.
graphql - is the library used to build a GraphQL schema and execute queries against it.
apollo-server-lambda - while apollo-server is used for creating a GraphQL server that you can deploy in your own cloud instance, apollo-server-lambda is a drop-in replacement if you want to deploy your server in AWS Lambda.
nodemon - watches for any changes and restarts your server when needed.
axios - our Http client of choice.
promise - library for helping us resolve our http requests.
dataloader - is a port of a library originally developed in Facebook to help in batching and caching requests in the server.
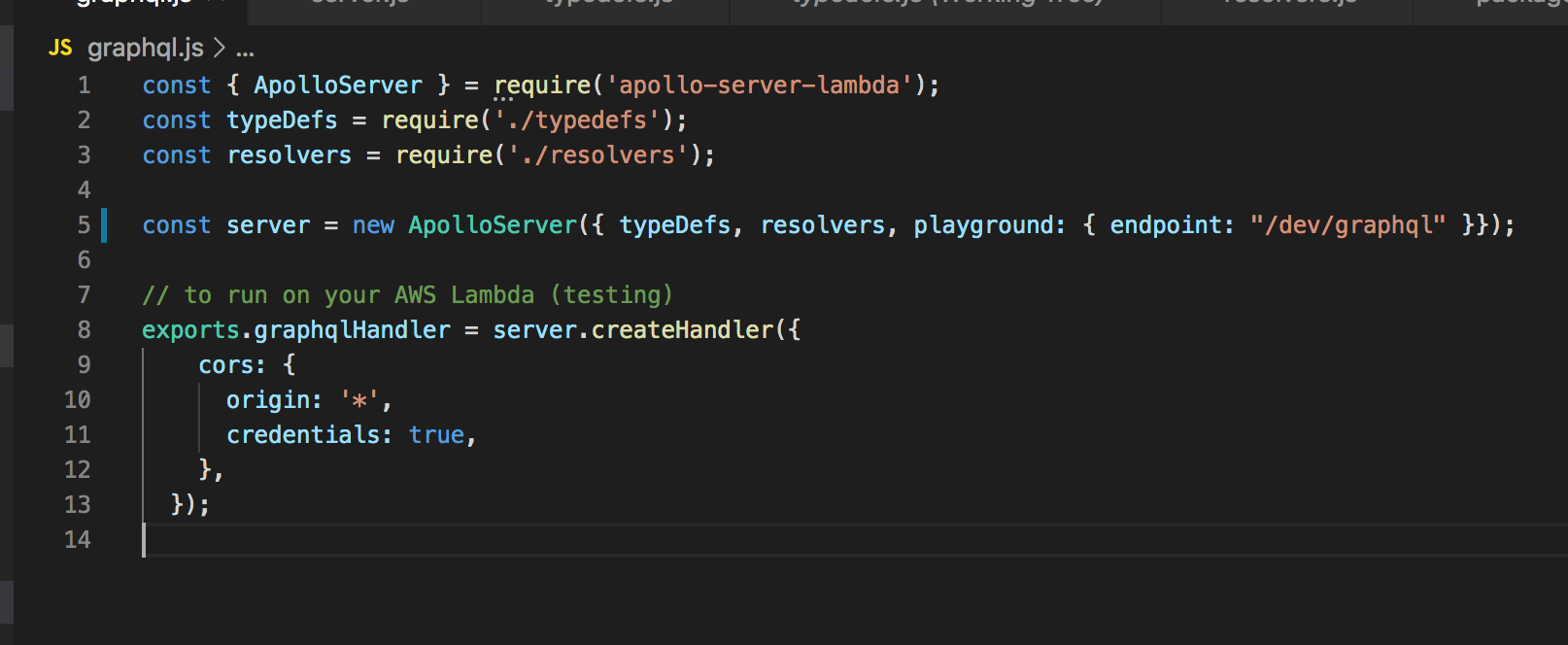
Now we need to work on some GraphQL specific tasks, starting with defining the schema. Schema is simply the shape of our data, both incoming and outgoing. This is what made me like working with GraphQL. Whether you are the server developer or on the other side of the fence as the client developer, it is a pleasure working with it.
1
2
3
4
5
6
7
8
9
10
11
12
13
type Result {
number: Int
position: Int
positionText: String
points: Float
Driver: Driver
Constructor: Constructor
grid: String
laps: Int
status: String
Time: Time
FastestLap: FastestLap
}
Have a look at the file typedefs.js - this file contains all the schema that the server uses, in addition to that, GraphQL introspection will also use these for self-documenting the API. The excerpt with type Result above shows the GraphQL SDL (Schema Definition Language), the type system used to express our data types.
GraphQL servers support 3 operations - Query (reads), Mutations (writes), and Subscriptions (pub-sub system). In this sample server, we will only be using Queries, and leave the other types, possibly for another post.
APIs build up data and send back to the client, and it’s no different with GraphQL. Our data sources may be varied - files, databases, web services, REST APIs, and other GraphQL servers themselves. A resolver collects and assembles the data and aggregates it before sending it back to the client.
For example, our server below supports the following 4 queries, however lets focus on the one named raceResults:
1
2
3
4
5
6
type Query {
results: [Result]
races: [Race]
raceResults(season: String!, resultsLimit: Int): [RaceResultV2]
seasons: [Season]
}
And the following shows the simplicity of building a resolver that fetches data from an API:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
raceResults(parent, args) {
const { season, resultsLimit } = args;
return axios
.get(`http://ergast.com/api/f1/${season}/results.json?limit=1000`)
.then(res => {
return res.data.MRData.RaceTable.Races.map((race) => {
return({
...race,
Results: race.Results.slice(0, resultsLimit || 1)
});
});
})
.catch(function (error) {
console.log(`Error: ${error}`);
});
}
Serverless makes it super simple to deploy your serverless applications to the cloud. Because its cloud agnostic, it can handle whatever cloud framework you use.
For this project, we will be deploying to AWS Lambda, and take advantage of their very generous free-tier, so we will never likely incur a bill.

Just setup your Serverless configuration in your project’s root, and because it has a CLI, you can deploy from your command line, or from your CI/CD of choice, in this case Github Actions, coming up next.
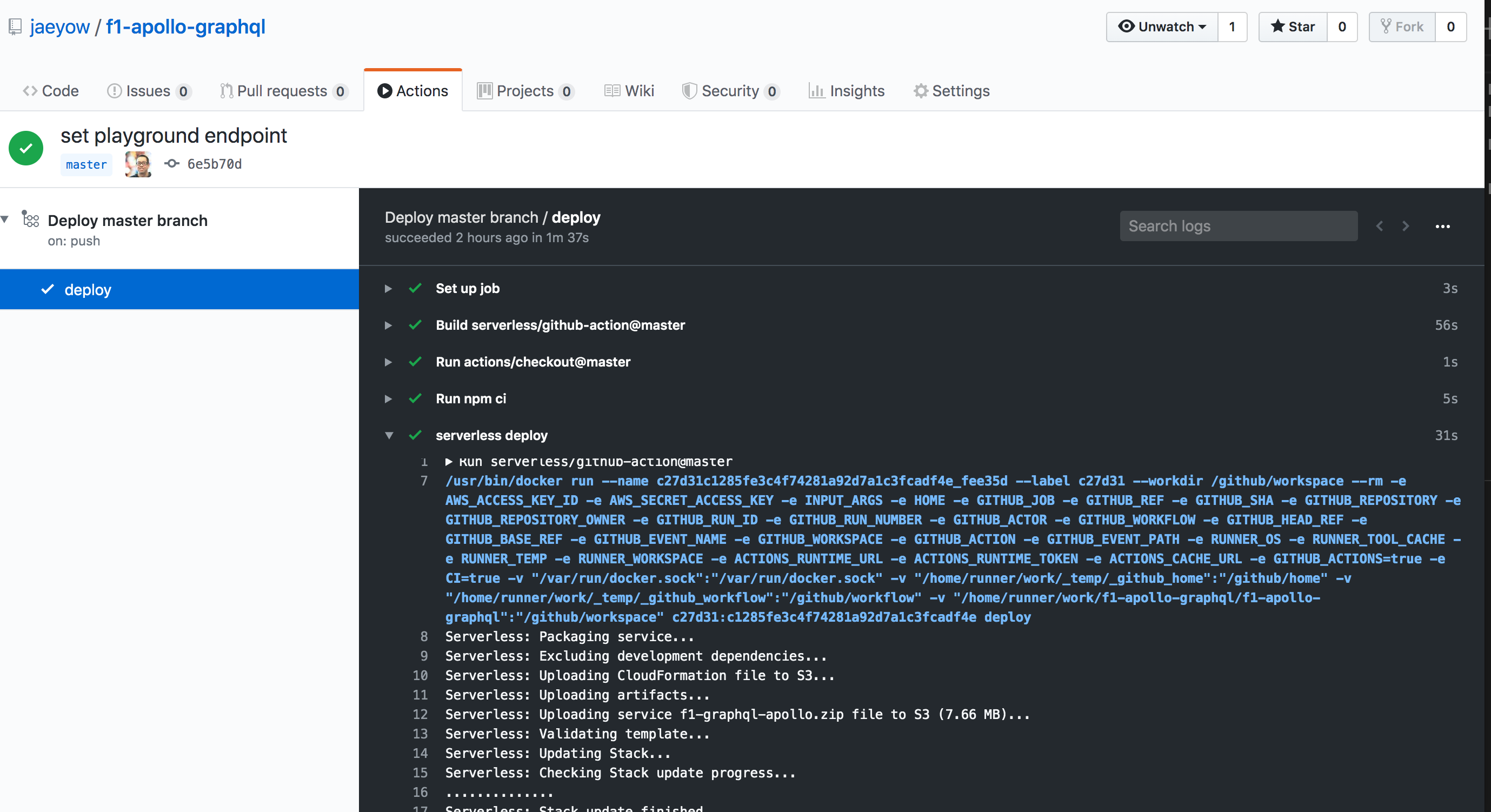
Github recently released Github Actions and ever since then, I have heard so many great things about it. Because this project lives in Github, wouldn’t it be awesome if the CI/CD lives there too? And its forever FREE for public repositories, so how good is that?!
If you have a private repository, you will have to fork out some $, however you still get get 2,000 minutes (33.3 hours) build time per month before you start handing in the dough.
So here’s our Github Actions deployment badge:
![]()
There you go, our first GraphQL server built with Apollo Server, NodeJS, Serverless, AWS Lambda and Github Actions, built and deployed on AWS for FREE!
Source code forever open-source
In our next GraphQL installment we will:
These picks are things that have had a positive impact to me in recent weeks:
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We then deploy the model to production in AWS.
We build a recommender system from the ground up with matrix factorization for implicit feedback systems. We put it all together with Metaflow and used Comet...
Building and maintaining a recommender system that is tuned to your business’ products or services can take great effort. The good news is that AWS can do th...
Provided in 6 weekly installments, we will cover current and relevant topics relating to ethics in data
Get your ML application to production quicker with Amazon Rekognition and AWS Amplify
(Re)Learning how to create conceptual models when building software
A scalable (and cost-effective) strategy to transition your Machine Learning project from prototype to production
An Approach to Effective and Scalable MLOps when you’re not a Giant like Google
Day 2 summary - AI/ML edition
Day 1 summary - AI/ML edition
What is Module Federation and why it’s perfect for building your Micro-frontend project
What you always wanted to know about Monorepos but were too afraid to ask
Using Github Actions as a practical (and Free*) MLOps Workflow tool for your Data Pipeline. This completes the Data Science Bootcamp Series
Final week of the General Assembly Data Science bootcamp, and the Capstone Project has been completed!
Fifth and Sixth week, and we are now working with Machine Learning algorithms and a Capstone Project update
Fourth week into the GA Data Science bootcamp, and we find out why we have to do data visualizations at all
On the third week of the GA Data Science bootcamp, we explore ideas for the Capstone Project
We explore Exploratory Data Analysis in Pandas and start thinking about the course Capstone Project
Follow along as I go through General Assembly’s 10-week Data Science Bootcamp
Updating Context will re-render context consumers, only in this example, it doesn’t
Static Site Generation, Server Side Render or Client Side Render, what’s the difference?
How to ace your Core Web Vitals without breaking the bank, hint, its FREE! With Netlify, Github and GatsbyJS.
Follow along as I implement DynamoDB Single-Table Design - find out the tools and methods I use to make the process easier, and finally the light-bulb moment...
Use DynamoDB as it was intended, now!
A GraphQL web client in ReactJS and Apollo
From source to cloud using Serverless and Github Actions
How GraphQL promotes thoughtful software development practices
Why you might not need external state management libraries anymore
My thoughts on the AWS Certified Developer - Associate Exam, is it worth the effort?
Running Lighthouse on this blog to identify opportunities for improvement
Use the power of influence to move people even without a title
Real world case studies on effects of improving website performance
Speeding up your site is easy if you know what to focus on. Follow along as I explore the performance optimization maze, and find 3 awesome tips inside (plus...
Tools for identifying performance gaps and formulating your performance budget
Why web performance matters and what that means to your bottom line
How to easily clear your Redis cache remotely from a Windows machine with Powershell
Trials with Docker and Umbraco for building a portable development environment, plus find 4 handy tips inside!
How to create a low cost, highly available CDN solution for your image handling needs in no time at all.
What is the BFF pattern and why you need it.